Введение
Добро пожаловать в Книгу по Embedded Rust: вводную книгу об использовании языка программирования Rust на "Bare Metal" встраиваемых системах, таких как микроконтроллеры.
Для кого предназначен Embedded Rust
Embedded Rust предназначен для всех, кто хочет заниматься встраиваемым программированием, используя преимущества концепций более высокого уровня и гарантий безопасности, предоставляемых языком Rust. (См. также Для кого предназначен Rust)
Область применения
Цели этой книги:
-
Помочь разработчикам быстро освоить разработку на embedded Rust. Т.е. как настроить среду разработки.
-
Поделиться текущими лучшими практиками использования Rust для разработки встраиваемых систем. Т.е. как лучше использовать функции языка Rust для написания более правильного ПО для встраиваемых систем.
-
Служить кулинарной книгой в некоторых случаях. Например, как смешать C и Rust в одном проекте?
Эта книга старается быть как можно более общей, но для облегчения как для читателей, так и для авторов она использует архитектуру ARM Cortex-M во всех примерах. Однако книга не предполагает, что читатель знаком с этой конкретной архитектурой, и объясняет детали, специфичные для этой архитектуры, где это необходимо.
Для кого эта книга
Эта книга ориентирована на людей с опытом либо в embedded-разработке, либо в Rust, однако мы считаем, что каждый, интересующийся embedded-программированием на Rust, может извлечь из этой книги пользу. Для тех, у кого нет предварительных знаний, мы предлагаем прочитать раздел "Предположения и предпосылки" и наверстать упущенные знания, чтобы получить больше от книги и улучшить опыт чтения. Вы можете посмотреть раздел "Другие ресурсы", чтобы найти материалы по темам, которые вы хотите наверстать.
Предположения и предпосылки
- Вы комфортно используете язык программирования Rust и написали, запустили и отлаживали приложения на Rust в десктопной среде. Вы также должны быть знакомы с идиомами [издания 2018 года], поскольку эта книга ориентирована на Rust 2018.
- Вы комфортно разрабатываете и отлаживаете встраиваемые системы на другом языке, таком как C, C++ или Ada, и знакомы с концепциями, такими как:
- Кросс-компиляция
- Периферийные устройства, отображенные в память
- Прерывания
- Общие интерфейсы, такие как I2C, SPI, Serial и т.д.
Другие ресурсы
Если вы не знакомы с чем-либо упомянутым выше или хотите больше информации по конкретной теме, упомянутой в этой книге, вы можете найти некоторые из этих ресурсов полезными.
| Тема | Ресурс | Описание |
|---|---|---|
| Rust | Книга по Rust | Если вы еще не комфортно владеете Rust, мы настоятельно рекомендуем прочитать эту книгу. |
| Rust, Embedded | Книга Discovery | Если вы никогда не занимались embedded-программированием, эта книга может быть лучшим стартом |
| Rust, Embedded | Полка книг по Embedded Rust | Здесь вы можете найти несколько других ресурсов, предоставленных рабочей группой Embedded Rust. |
| Rust, Embedded | Embedonomicon | Детали embedded-программирования на Rust. |
| Rust, Embedded | FAQ по embedded | Часто задаваемые вопросы по Rust в embedded. |
| Встраиваемое программирование | Курс на Coursera | Бесплатный курс на Coursera по встраиваемым системам. |
| Встраиваемое программирование | Курс на edX | Бесплатный курс на edX по встраиваемым системам. |
| Прерывания | Прерывание | - |
| Отображение ввода/вывода в память/Периферийные устройства | Отображение ввода/вывода в память | - |
| SPI, UART, RS232, USB, I2C, TTL | Stack Exchange о SPI, UART и других интерфейсах | - |
Переводы
Эта книга переведена щедрыми добровольцами. Если вы хотите, чтобы ваш перевод был перечислен здесь, пожалуйста, откройте PR, чтобы добавить его.
Как использовать эту книгу
Эта книга в целом предполагает, что вы читаете ее от начала до конца. Более поздние главы строятся на концепциях из ранних глав, и ранние главы могут не углубляться в детали темы, возвращаясь к ней в более поздней главе.
Эта книга будет использовать плату разработки STM32F3DISCOVERY от STMicroelectronics для большинства примеров. Эта плата основана на архитектуре ARM Cortex-M, и хотя базовая функциональность одинакова для большинства CPU на этой архитектуре, периферийные устройства и другие детали реализации микроконтроллеров отличаются между разными производителями и даже между семьями микроконтроллеров от одного производителя.
По этой причине мы рекомендуем приобрести плату разработки STM32F3DISCOVERY для следования примерам в этой книге.
Вклад в эту книгу
Работа над этой книгой координируется в этом репозитории и в основном разрабатывается командой ресурсов.
Если у вас проблемы со следующими инструкциями в этой книге или вы находите, что какой-то раздел книги недостаточно ясен или трудно следовать, то это ошибка, и ее следует сообщить в отслеживателе задач этой книги.
Пулл-реквесты, исправляющие опечатки и добавляющие новый контент, очень приветствуются!
Переиспользование этого материала
Эта книга распространяется под следующими лицензиями:
- Примеры кода и отдельные проекты Cargo, содержащиеся в этой книге, лицензированы на условиях как [лицензии MIT], так и [лицензии Apache v2.0].
- Проза, изображения и диаграммы, содержащиеся в этой книге, лицензированы на условиях лицензии Creative Commons CC-BY-SA v4.0.
Коротко: Если вы хотите использовать наш текст или изображения в своей работе, вам нужно:
- Дать соответствующую атрибуцию (т.е. упомянуть эту книгу на вашем слайде и предоставить ссылку на соответствующую страницу)
- Предоставить ссылку на лицензию CC-BY-SA v4.0
- Указать, если вы изменили материал каким-либо образом, и сделать любые изменения в нашем материале доступными под той же лицензией
Также, пожалуйста, дайте нам знать, если вы находите эту книгу полезной!
Знакомство с аппаратным обеспечением
Давайте познакомимся с аппаратным обеспечением, с которым мы будем работать.
STM32F3DISCOVERY ( "F3")

Что содержит эта плата?
-
Микроконтроллер STM32F303VCT6. Этот микроконтроллер имеет
-
Одноядерный процессор ARM Cortex-M4F с аппаратной поддержкой операций с плавающей запятой одинарной точности и максимальной тактовой частотой 72 МГц.
-
256 КБ "Flash" памяти. (1 КБ = 1024 байта)
-
48 КБ ОЗУ.
-
Разнообразные интегрированные периферийные устройства, такие как таймеры, I2C, SPI и USART.
-
Ввод/вывод общего назначения (GPIO) и другие типы пинов, доступные через две ряда заголовков вдоль края платы.
-
Интерфейс USB, доступный через порт USB с меткой "USB USER".
-
-
Акцелерометр как часть чипа LSM303DLHC.
-
Магнитометр как часть чипа LSM303DLHC.
-
Гироскоп как часть чипа L3GD20.
-
8 пользовательских светодиодов, расположенных в форме компаса.
-
Второй микроконтроллер: STM32F103. Этот микроконтроллер на самом деле является частью встроенного программатора/отладчика и подключен к порту USB с меткой "USB ST-LINK".
Для более подробного списка функций и дальнейших спецификаций платы посмотрите на сайте STMicroelectronics.
Слово предосторожности: будьте осторожны, если хотите применять внешние сигналы к плате. Пины микроконтроллера STM32F303VCT6 принимают номинальное напряжение 3.3 вольта. Для дополнительной информации обратитесь к разделу 6.2 Absolute maximum ratings в руководстве
Окружение Rust с no_std
Термин "встраиваемое программирование" используется для широкого спектра классов программирования. От программирования 8-битных микроконтроллеров (например, ST72325xx) с всего несколькими КБ ОЗУ и ПЗУ до систем вроде Raspberry Pi (Model B 3+), которая имеет 32/64-битный 4-ядерный процессор Cortex-A53 с частотой 1.4 ГГц и 1 ГБ ОЗУ. Разные ограничения применяются при написании кода в зависимости от цели и случая использования.
Существуют два общих класса встраиваемого программирования:
Хостинговые окружения
Такие окружения близки к обычному окружению ПК. Это означает, что предоставляется системный интерфейс например, POSIX, который дает примитивы для взаимодействия с различными системами, такими как файловые системы, сеть, управление памятью, потоки и т.д. Стандартные библиотеки, в свою очередь, обычно зависят от этих примитивов для реализации своей функциональности. Также может быть sysroot и ограничения на использование ОЗУ/ПЗУ, а также специальное оборудование или ввод/вывод. В целом это похоже на программирование в специальной среде ПК.
Окружения без ОС (Bare Metal)
В окружении без ОС (bare metal) перед вашей программой не загружено никакого кода.
Без ПО, предоставляемого ОС, мы не можем загрузить стандартную библиотеку.
Вместо этого программа вместе с используемыми крейтами может использовать только аппаратное обеспечение (bare metal) для выполнения.
Чтобы предотвратить загрузку стандартной библиотеки Rust, используйте no_std.
Части стандартной библиотеки, не зависящие от платформы, доступны через libcore.
libcore также исключает вещи, которые не всегда желательны в окружении встраиваемых систем.
Одна из них — распределитель памяти для динамического выделения памяти.
Если требуется это или другие функциональности, часто есть крейты, которые их предоставляют.
Runtime libstd
Как упоминалось ранее, использование libstd требует некоторой системной интеграции, но не только потому,
что libstd просто предоставляет общий способ доступа к абстракциям ОС, она также предоставляет runtime.
Эта runtime, среди прочего, настраивает защиту от переполнения стека, обрабатывает аргументы командной строки
и порождает основной поток перед вызовом главной функции программы. Эта runtime также недоступна в окружении no_std.
Итог
#![no_std] — это атрибут на уровне крейта, указывающий, что крейт будет ссылаться на крейт core вместо std.
Крейт libcore, в свою очередь, — это подмножество std, не зависящее от платформы,
которое не делает предположений о системе, на которой будет работать программа.
Таким образом, он предоставляет API для языковых примитивов, таких как числа с плавающей запятой, строки и слайсы, а также API, раскрывающие функции процессора,
такие как атомарные операции и инструкции SIMD. Однако он не предоставляет API для чего-либо, что включает интеграцию с платформой.
Благодаря этим свойствам код с no_std и libcore может использоваться для любого вида
загрузочного (stage 0) кода, такого как загрузчики, прошивки или ядра.
Обзор
| Функция | no_std | std |
|---|---|---|
| куча (динамическая память) | * | ✓ |
| коллекции (Vec, BTreeMap и т.д.) | ** | ✓ |
| защита от переполнения стека | ✘ | ✓ |
| выполнение кода инициализации перед main | ✘ | ✓ |
| доступна libstd | ✘ | ✓ |
| доступна libcore | ✓ | ✓ |
| написание прошивки, ядра или кода загрузчика | ✓ | ✘ |
* Только если вы используете крейт alloc и подходящий распределитель, такой как alloc-cortex-m.
** Только если вы используете крейт collections и настраиваете глобальный распределитель по умолчанию.
** HashMap и HashSet недоступны из-за отсутствия безопасного генератора случайных чисел.
См. также
Инструменты
Работа с микроконтроллерами включает использование нескольких различных инструментов, поскольку мы имеем дело с архитектурой, отличной от вашего ноутбука, и нам придется запускать и отлаживать программы на удаленном устройстве.
Мы будем использовать все перечисленные ниже инструменты. Любая недавняя версия должна работать, если не указана минимальная версия, но мы перечислили протестированные версии.
- Rust 1.31, 1.31-beta или более новая цепочка инструментов ПЛЮС поддержка компиляции для ARM Cortex-M.
cargo-binutils~0.1.4qemu-system-arm. Протестированные версии: 3.0.0- OpenOCD >=0.8. Протестированные версии: v0.9.0 и v0.10.0
- GDB с поддержкой ARM. Рекомендуется версия 7.12 или новее. Протестированные версии: 7.10, 7.11, 7.12 и 8.1
cargo-generateилиgit. Эти инструменты опциональны, но облегчат следование книге.
Текст ниже объясняет, почему мы используем эти инструменты. Инструкции по установке можно найти на следующей странице.
cargo-generate ИЛИ git
Программы без ОС (bare metal) — это нестандартные (no_std) программы на Rust, требующие некоторых корректировок процесса линковки для правильной компоновки памяти. Это требует дополнительных файлов (таких как скрипты линковки) и настроек (таких как флаги линковки). Мы упаковали их для вас в шаблон, так что вам нужно только заполнить недостающую информацию (например, имя проекта и характеристики целевого оборудования).
Наш шаблон совместим с cargo-generate: подкомандой Cargo для создания новых проектов Cargo из шаблонов. Вы также можете скачать шаблон с помощью git, curl, wget или вашего веб-браузера.
cargo-binutils
cargo-binutils — это коллекция подкоманд Cargo, облегчающих использование инструментов LLVM, поставляемых с цепочкой инструментов Rust. Эти инструменты включают версии LLVM objdump, nm и size и используются для инспекции бинарных файлов.
Преимущество использования этих инструментов перед GNU binutils заключается в том, что (a) установка инструментов LLVM — это одна команда (rustup component add llvm-tools) независимо от вашей ОС и (b) инструменты вроде objdump поддерживают все архитектуры, поддерживаемые rustc — от ARM до x86_64 — поскольку они оба используют один и тот же бэкенд LLVM.
qemu-system-arm
QEMU — это эмулятор. В данном случае мы используем вариант, который может полностью эмулировать системы ARM. Мы используем QEMU для запуска программ для встраиваемых систем на хосте. Благодаря этому вы можете следовать некоторым частям этой книги, даже если у вас нет оборудования!
Инструменты для отладки Embedded Rust
Обзор
Отладка встраиваемых систем в Rust требует специализированных инструментов, включая ПО для управления процессом отладки, отладчики для инспекции и управления выполнением программы, а также аппаратные пробники для взаимодействия между хостом и встраиваемым устройством. Этот документ описывает основные программные инструменты, такие как Probe-rs и OpenOCD, которые упрощают и поддерживают процесс отладки, а также известные отладчики, такие как GDB и расширение Probe-rs для Visual Studio Code. Кроме того, он охватывает ключевые аппаратные пробники, такие как Rusty-probe, ST-Link, J-Link и MCU-Link, которые необходимы для эффективной отладки и программирования встраиваемых устройств.
ПО, управляющее инструментами отладки
Probe-rs
Probe-rs — это современное ПО, ориентированное на Rust, предназначенное для работы с отладчиками во встраиваемых системах. В отличие от OpenOCD, Probe-rs разработан с учетом простоты и стремится уменьшить нагрузку на конфигурацию, часто встречающуюся в других решениях отладки. Он поддерживает различные пробники и цели, предоставляя высокоуровневый интерфейс для взаимодействия со встраиваемыми системами. Probe-rs позволяет разработчикам устанавливать точки останова, шагать по коду и исследовать состояние памяти и регистров процессора. Он интегрируется с популярными IDE, такими как Visual Studio Code, и поддерживает функции, специфичные для Rust, такие как красивая печать и детализированные сообщения об ошибках.
OpenOCD
OpenOCD (Open On-Chip Debugger) — это открытое ПО для отладки и программирования встраиваемых систем. Оно поддерживает широкий спектр аппаратных пробников и микроконтроллеров, позволяя разработчикам взаимодействовать с целевыми устройствами через интерфейсы вроде JTAG или SWD. OpenOCD служит сервером отладки, который может подключаться к отладчикам вроде GDB, предоставляя низкоуровневый доступ к регистрам, памяти и периферийным устройствам микроконтроллера. Он высоко конфигурируем и используется в различных окружениях разработки для встраиваемых систем.
Отладчики
Отладчики — это инструменты, позволяющие разработчикам проверять состояние программ во время выполнения или после сбоя. Они предоставляют функциональности, такие как установка точек останова, шагание по коду строка за строкой и исследование значений переменных и состояний памяти. Отладчики необходимы для тщательной разработки и обслуживания ПО, позволяя разработчикам убедиться, что их код ведет себя как ожидается в различных условиях.
Отладчики знают, как:
- Взаимодействовать с регистрами, отображенными в память.
- Устанавливать точки останова/наблюдения.
- Читать и писать в регистры, отображенные в память.
- Обнаруживать, когда микроконтроллер остановлен для события отладки.
- Продолжать выполнение микроконтроллера после события отладки.
- Стирать и записывать в FLASH микроконтроллера.
Расширение Probe-rs для Visual Studio Code
Probe-rs имеет расширение для Visual Studio Code, предоставляющее seamless опыт отладки без обширной настройки. Через это соединение разработчики могут использовать функции, специфичные для Rust, такие как красивая печать и детализированные сообщения об ошибках, обеспечивая, что процесс отладки соответствует экосистеме Rust.
GDB (GNU Debugger)
GDB — это универсальный инструмент отладки, позволяющий разработчикам проверять состояние программ во время выполнения или после сбоя. Для embedded Rust GDB подключается к целевой системе через OpenOCD или другие серверы отладки для взаимодействия с кодом встраиваемой системы. GDB высоко конфигурируем и поддерживает функции вроде удаленной отладки, инспекции переменных и условных точек останова. Он может использоваться на различных платформах и имеет обширную поддержку нужд отладки, специфичных для Rust, таких как красивая печать и интеграция с IDE.
Пробники
Аппаратный пробник — это устройство, используемое в разработке и отладке встраиваемых систем для облегчения коммуникации между хост-компьютером и целевым встраиваемым устройством. Он обычно поддерживает протоколы вроде JTAG или SWD, позволяя программировать, отлаживать и анализировать микроконтроллер или микропроцессор на встраиваемой системе. Аппаратные пробники критичны для разработчиков, чтобы устанавливать точки останова, шагать по коду и инспектировать память и регистры процессора, эффективно позволяя диагностировать и исправлять проблемы в реальном времени.
Rusty-probe
Rusty-probe — это открытый USB-основанный аппаратный пробник отладки, предназначенный для работы с probe-rs. Комбинация Rusty-Probe и probe-rs предоставляет простое в использовании, экономичное решение для разработчиков, работающих с приложениями embedded Rust.
ST-Link
ST-Link — это популярный пробник отладки и программирования, разработанный STMicroelectronics в основном для серий микроконтроллеров STM32 и STM8. Он поддерживает отладку и программирование через интерфейсы JTAG или SWD (Serial Wire Debug). ST-Link широко используется благодаря прямой поддержке от STMicroelectronics для широкого спектра плат разработки и интеграции в основные IDE, делая его удобным выбором для разработчиков, работающих с микроконтроллерами STM.
J-Link
J-Link, разработанный SEGGER Microcontroller, — это надежный и универсальный отладчик, поддерживающий широкий спектр ядер CPU и устройств за пределами ARM, таких как RISC-V. Известный своей высокой производительностью и надежностью, J-Link поддерживает различные интерфейсы связи, включая JTAG, SWD и fine-pitch JTAG. Он популярен благодаря продвинутым функциям, таким как неограниченные точки останова в flash-памяти и совместимость с множеством сред разработки.
MCU-Link
MCU-Link — это пробник отладки, который также функционирует как программатор, предоставляемый NXP Semiconductors. Он поддерживает разнообразные микроконтроллеры ARM Cortex и seamless интегрируется с инструментами разработки вроде MCUXpresso IDE. MCU-Link особенно известен своей универсальностью и доступностью, делая его доступным вариантом для хоббиистов, преподавателей и профессиональных разработчиков.
Установка инструментов
Эта страница содержит инструкции по установке некоторых инструментов, не зависящие от ОС:
Цепочка инструментов Rust
Установите rustup, следуя инструкциям на https://rustup.rs.
ПРИМЕЧАНИЕ Убедитесь, что у вас версия компилятора не ниже 1.31. Команда rustc -V должна возвращать дату новее указанной ниже.
$ rustc -V
rustc 1.31.1 (b6c32da9b 2018-12-18)
Для экономии трафика и места на диске установка по умолчанию поддерживает только нативную компиляцию. Чтобы добавить поддержку кросс-компиляции для архитектур ARM Cortex-M, выберите один из следующих целевых объектов компиляции. Для платы STM32F3DISCOVERY, используемой в примерах этой книги, используйте цель thumbv7em-none-eabihf.
Найдите подходящий Cortex-M для вас.
Cortex-M0, M0+ и M1 (архитектура ARMv6-M):
rustup target add thumbv6m-none-eabi
Cortex-M3 (архитектура ARMv7-M):
rustup target add thumbv7m-none-eabi
Cortex-M4 и M7 без аппаратной поддержки операций с плавающей запятой (архитектура ARMv7E-M):
rustup target add thumbv7em-none-eabi
Cortex-M4F и M7F с аппаратной поддержкой операций с плавающей запятой (архитектура ARMv7E-M):
rustup target add thumbv7em-none-eabihf
Cortex-M23 (архитектура ARMv8-M):
rustup target add thumbv8m.base-none-eabi
Cortex-M33 и M35P (архитектура ARMv8-M):
rustup target add thumbv8m.main-none-eabi
Cortex-M33F и M35PF с аппаратной поддержкой операций с плавающей запятой (архитектура ARMv8-M):
rustup target add thumbv8m.main-none-eabihf
cargo-binutils
cargo install cargo-binutils
rustup component add llvm-tools
WINDOWS: убедитесь, что установлены C++ Build Tools для Visual Studio 2019. https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=BuildTools&rel=16
cargo-generate
Мы используем это позже для генерации проекта из шаблона.
cargo install cargo-generate
Примечание: в некоторых дистрибутивах Linux (например, Ubuntu) может потребоваться установка пакетов libssl-dev и pkg-config перед установкой cargo-generate.
Инструкции, специфичные для ОС
Теперь следуйте инструкциям, специфичным для вашей ОС:
Linux
Вот команды установки для нескольких дистрибутивов Linux.
Пакеты
- Ubuntu 18.04 или новее / Debian stretch или новее
ПРИМЕЧАНИЕ
gdb-multiarch— это команда GDB, которую вы будете использовать для отладки программ для ARM Cortex-M
sudo apt install gdb-multiarch openocd qemu-system-arm
- Ubuntu 14.04 и 16.04
ПРИМЕЧАНИЕ
arm-none-eabi-gdb— это команда GDB, которую вы будете использовать для отладки программ для ARM Cortex-M
sudo apt install gdb-arm-none-eabi openocd qemu-system-arm
- Fedora 27 или новее
sudo dnf install gdb openocd qemu-system-arm
- Arch Linux
ПРИМЕЧАНИЕ
arm-none-eabi-gdb— это команда GDB, которую вы будете использовать для отладки программ для ARM Cortex-M
sudo pacman -S arm-none-eabi-gdb qemu-system-arm openocd
Правила udev
Это правило позволяет использовать OpenOCD с платой Discovery без привилегий root.
Создайте файл /etc/udev/rules.d/70-st-link.rules с содержимым, показанным ниже.
# STM32F3DISCOVERY rev A/B - ST-LINK/V2
ATTRS{idVendor}=="0483", ATTRS{idProduct}=="3748", TAG+="uaccess"
# STM32F3DISCOVERY rev C+ - ST-LINK/V2-1
ATTRS{idVendor}=="0483", ATTRS{idProduct}=="374b", TAG+="uaccess"
Затем перезагрузите все правила udev с помощью:
sudo udevadm control --reload-rules
Если плата была подключена к вашему ноутбуку, отключите ее и подключите заново.
Вы можете проверить разрешения, выполнив эту команду:
lsusb
Которая должна показать что-то вроде
(..)
Bus 001 Device 018: ID 0483:374b STMicroelectronics ST-LINK/V2.1
(..)
Запишите номера шины и устройства. Используйте эти номера для создания пути вроде /dev/bus/usb/<bus>/<device>. Затем используйте этот путь так:
ls -l /dev/bus/usb/001/018
crw-------+ 1 root root 189, 17 Sep 13 12:34 /dev/bus/usb/001/018
getfacl /dev/bus/usb/001/018 | grep user
user::rw-
user:you:rw-
+, добавленный к разрешениям, указывает на наличие расширенного разрешения. Команда getfacl показывает, что пользователь you может использовать это устройство.
Теперь перейдите к следующему разделу.
macOS
Все инструменты можно установить с помощью Homebrew или MacPorts:
Установка инструментов с Homebrew
$ # GDB
$ brew install arm-none-eabi-gdb
$ # OpenOCD
$ brew install openocd
$ # QEMU
$ brew install qemu
ПРИМЕЧАНИЕ Если OpenOCD падает, может потребоваться установка последней версии с помощью:
$ brew install --HEAD openocd
Установка инструментов с MacPorts
$ # GDB
$ sudo port install arm-none-eabi-gcc
$ # OpenOCD
$ sudo port install openocd
$ # QEMU
$ sudo port install qemu
Это все! Перейдите к следующему разделу.
Windows
arm-none-eabi-gdb
ARM предоставляет установщики .exe для Windows. Возьмите один отсюда gcc и следуйте инструкциям.
Непосредственно перед завершением процесса установки отметьте опцию "Add path to environment variable".
Затем проверьте, что инструменты в вашем %PATH%:
$ arm-none-eabi-gdb -v
GNU gdb (GNU Tools for Arm Embedded Processors 7-2018-q2-update) 8.1.0.20180315-git
(..)
OpenOCD
Официального бинарного релиза OpenOCD для Windows нет, но если вы не в настроении компилировать его самостоятельно, проект xPack предоставляет бинарную дистрибуцию здесь. Следуйте предоставленным инструкциям по установке. Затем обновите переменную окружения %PATH%, чтобы включить путь, куда были установлены бинарные файлы. (C:\Users\USERNAME\AppData\Roaming\xPacks\@xpack-dev-tools\openocd\0.10.0-13.1\.content\bin\,
если вы использовали простую установку)
Проверьте, что OpenOCD в вашем %PATH% с помощью:
$ openocd -v
Open On-Chip Debugger 0.10.0
(..)
QEMU
Возьмите QEMU с официального сайта.
Драйвер USB ST-LINK
Вам также потребуется установить этот драйвер USB, иначе OpenOCD не будет работать. Следуйте инструкциям установщика и убедитесь, что устанавливаете правильную версию (32-битную или 64-битную) драйвера.
Это все! Перейдите к следующему разделу.
Проверка установки
В этом разделе мы проверяем, что некоторые требуемые инструменты / драйверы были правильно установлены и настроены.
Подключите ваш ноутбук / ПК к плате discovery с помощью кабеля Mini-USB. Плата discovery имеет два разъема USB; используйте тот, с меткой "USB ST-LINK", который находится в центре края платы.
Также проверьте, что заголовок ST-LINK установлен. Смотрите картинку ниже; заголовок ST-LINK выделен.

Теперь выполните следующую команду:
openocd -f interface/stlink.cfg -f target/stm32f3x.cfg
ПРИМЕЧАНИЕ: Старые версии openocd, включая релиз 0.10.0 от 2017 года, не содержат новый (и предпочтительный) файл
interface/stlink.cfg; вместо этого может потребоваться использоватьinterface/stlink-v2.cfgилиinterface/stlink-v2-1.cfg.
Вы должны получить следующий вывод, и программа заблокирует консоль:
Open On-Chip Debugger 0.10.0
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : auto-selecting first available session transport "hla_swd". To override use 'transport select <transport>'.
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
Info : The selected transport took over low-level target control. The results might differ compared to plain JTAG/SWD
none separate
Info : Unable to match requested speed 1000 kHz, using 950 kHz
Info : Unable to match requested speed 1000 kHz, using 950 kHz
Info : clock speed 950 kHz
Info : STLINK v2 JTAG v27 API v2 SWIM v15 VID 0x0483 PID 0x374B
Info : using stlink api v2
Info : Target voltage: 2.919881
Info : stm32f3x.cpu: hardware has 6 breakpoints, 4 watchpoints
Содержимое может не совпадать точно, но вы должны получить последнюю строку о точках останова и наблюдения. Если вы получили ее, завершите процесс OpenOCD и перейдите к следующему разделу.
Если вы не получили строку "breakpoints", попробуйте одну из следующих команд.
openocd -f interface/stlink-v2.cfg -f target/stm32f3x.cfg
openocd -f interface/stlink-v2-1.cfg -f target/stm32f3x.cfg
Если одна из этих команд работает, это значит, что у вас старая аппаратная ревизия платы discovery. Это не будет проблемой, но запомните этот факт, поскольку вам потребуется немного по-другому настроить вещи позже. Вы можете перейти к следующему разделу.
Если ни одна из команд не работает от обычного пользователя, попробуйте запустить их с правами root (например, sudo openocd ..). Если команды работают с правами root, проверьте, что правила udev установлены правильно.
Если вы дошли до этого момента и OpenOCD не работает, пожалуйста, откройте issue, и мы поможем вам!
Начало работы
В этом разделе мы проведем вас через процесс написания, сборки, прошивки и отладки встраиваемых программ. Вы сможете попробовать большинство примеров без специального оборудования, поскольку мы покажем основы с использованием QEMU, популярного эмулятора аппаратного обеспечения с открытым исходным кодом. Единственный раздел, где требуется оборудование, — это, естественно, раздел Аппаратное обеспечение, где мы используем OpenOCD для программирования платы STM32F3DISCOVERY.
QEMU
Мы начнем с написания программы для LM3S6965, микроконтроллера Cortex-M3. Мы выбрали его в качестве начальной цели, потому что он может быть эмулирован с использованием QEMU, так что в этом разделе вам не придется возиться с оборудованием, и мы сможем сосредоточиться на инструментах и процессе разработки.
ВАЖНО
В этом руководстве мы будем использовать имя "app" для проекта. Везде, где вы видите слово "app", заменяйте его на имя, которое вы выбрали для своего проекта. Или вы можете назвать свой проект "app" и избежать замен.
Создание нестандартной программы на Rust
Мы будем использовать шаблон проекта cortex-m-quickstart для создания нового проекта. Созданный проект будет содержать базовое приложение: хорошую отправную точку для нового встраиваемого приложения на Rust. Кроме того, проект будет содержать директорию examples с несколькими отдельными приложениями, демонстрирующими ключевые функции встраиваемого Rust.
Использование cargo-generate
Сначала установите cargo-generate:
cargo install cargo-generate
Затем создайте новый проект:
cargo generate --git https://github.com/rust-embedded/cortex-m-quickstart
Project Name: app
Creating project called `app`...
Done! New project created /tmp/app
cd app
Использование git
Склонируйте репозиторий:
git clone https://github.com/rust-embedded/cortex-m-quickstart app
cd app
Затем заполните заполнители в файле Cargo.toml:
[package]
authors = ["{{authors}}"] # "{{authors}}" -> "John Smith"
edition = "2018"
name = "{{project-name}}" # "{{project-name}}" -> "app"
version = "0.1.0"
Теперь давайте настроим отладку в GDB, чтобы увидеть, как работает программа. Мы будем использовать пример hello.rs из директории examples.
Сначала скомпилируйте пример:
cargo build --example hello
Запустите QEMU в одном терминале:
cargo run --example hello
В другом терминале запустите GDB:
arm-none-eabi-gdb target/thumbv7m-none-eabi/debug/examples/hello
В GDB подключитесь к QEMU:
(gdb) target remote :1234
Теперь вы можете установить точку останова на функции Reset, которая является точкой входа программы:
(gdb) break Reset
Breakpoint 1 at 0x8000942: file src/lib.rs, line 473.
Запустите программу до точки останова:
(gdb) continue
Continuing.
Breakpoint 1, app::__cortex_m_rt_reset () at src/lib.rs:473
473 unsafe extern "C" fn Reset() -> ! {
ПРИМЕЧАНИЕ: Если при установке точки останова на
Reset, как показано выше, GDB выдает предупреждения вроде:
core::num::bignum::Big32x40::mul_small () at src/libcore/num/bignum.rs:254
src/libcore/num/bignum.rs: No such file or directory.Это известная ошибка. Вы можете спокойно игнорировать эти предупреждения, скорее всего, вы находитесь в
Reset().
Этот обработчик сброса в конечном итоге вызовет нашу основную функцию. Давайте пропустим все до нее, используя точку останова и команду continue. Сначала посмотрим, где мы хотим установить точку останова, с помощью команды list:
list main
Это покажет исходный код из файла examples/hello.rs:
6 use panic_halt as _;
7
8 use cortex_m_rt::entry;
9 use cortex_m_semihosting::{debug, hprintln};
10
11 #[entry]
12 fn main() -> ! {
13 hprintln!("Hello, world!").unwrap();
14
15 // Выход из QEMU
Мы хотим установить точку останова перед "Hello, world!", которая находится на строке 13. Сделайте это с помощью команды break:
break 13
Теперь мы можем указать GDB запустить программу до нашей основной функции с помощью команды continue:
continue
Continuing.
Breakpoint 1, hello::__cortex_m_rt_main () at examples\hello.rs:13
13 hprintln!("Hello, world!").unwrap();
Теперь мы близки к коду, который выводит "Hello, world!". Давайте продвинемся вперед с помощью команды next:
next
16 debug::exit(debug::EXIT_SUCCESS);
На этом этапе вы должны увидеть "Hello, world!" в терминале, где запущен qemu-system-arm:
$ qemu-system-arm (..)
Hello, world!
Вызов next еще раз завершит процесс QEMU:
next
[Inferior 1 (Remote target) exited normally]
Теперь вы можете выйти из сессии GDB:
quit
Аппаратное обеспечение
К этому моменту вы уже должны быть немного знакомы с инструментами и процессом разработки. В этом разделе мы перейдем к реальному аппаратному обеспечению; процесс останется в основном тем же. Давайте начнем.
Знайте ваше оборудование
Перед началом вам нужно определить некоторые характеристики целевого устройства, поскольку они будут использоваться для настройки проекта:
- Ядро ARM. Например, Cortex-M3.
- Есть ли у ядра ARM FPU? Ядра Cortex-M4F и Cortex-M7F имеют FPU.
- Сколько флэш-памяти и оперативной памяти имеет целевое устройство? Например, 256 КиБ флэш-памяти и 32 КиБ оперативной памяти.
- Где отображаются флэш-память и оперативная память в адресном пространстве? Например, оперативная память обычно располагается по адресу
0x2000_0000.
Эту информацию можно найти в техническом описании или справочном руководстве вашего устройства.
В этом разделе мы будем использовать наше эталонное оборудование — плату STM32F3DISCOVERY. Эта плата содержит микроконтроллер STM32F303VCT6. Этот микроконтроллер имеет:
- Ядро Cortex-M4F с однопрецизионным FPU.
- 256 КиБ флэш-памяти, расположенной по адресу
0x0800_0000. - 40 КиБ оперативной памяти, расположенной по адресу
0x2000_0000. (Есть еще одна область оперативной памяти, но для простоты мы ее проигнорируем).
Настройка
Мы начнем с нуля с новым экземпляром шаблона. Обратитесь к [предыдущему разделу о QEMU] для напоминания о том, как это сделать без использования cargo-generate.
$ cargo generate --git https://github.com/rust-embedded/cortex-m-quickstart
Project Name: app
Creating project called `app`...
Done! New project created /tmp/app
$ cd app
Первым шагом является установка целевого компилятора по умолчанию в файле .cargo/config.toml.
tail -n5 .cargo/config.toml
# Выберите ОДИН из этих целей компиляции
# target = "thumbv6m-none-eabi...
Теперь нам нужно создать GDB-скрипт для загрузки программы и взаимодействия с платой. В шаблоне уже есть один GDB-скрипт с именем openocd.gdb, созданный на этапе cargo generate, и он должен работать без изменений. Давайте взглянем на него:
cat openocd.gdb
target extended-remote :3333
# Печать деманглированных символов
set print asm-demangle on
# Обнаружение необработанных исключений, жестких сбоев и паник
break DefaultHandler
break HardFault
break rust_begin_unwind
monitor arm semihosting enable
load
# Запуск процесса с немедленной остановкой процессора
stepi
Теперь выполнение команды <gdb> -x openocd.gdb target/thumbv7em-none-eabihf/debug/examples/hello немедленно подключит GDB к OpenOCD, включит семихостинг, загрузит программу и запустит процесс.
Альтернативно, вы можете превратить <gdb> -x openocd.gdb в пользовательский запускатель, чтобы cargo run одновременно компилировал программу и запускал сессию GDB. Этот запускатель включен в .cargo/config.toml, но закомментирован.
head -n10 .cargo/config.toml
[target.thumbv7m-none-eabi]
# Раскомментируйте это, чтобы `cargo run` запускал программы на QEMU
# runner = "qemu-system-arm -cpu cortex-m3 -machine lm3s6965evb -nographic -semihosting-config enable=on,target=native -kernel"
[target.'cfg(all(target_arch = "arm", target_os = "none"))']
# Раскомментируйте ОДИН из этих трех вариантов, чтобы `cargo run` запускал сессию GDB
# Какой вариант выбрать, зависит от вашей системы
runner = "arm-none-eabi-gdb -x openocd.gdb"
# runner = "gdb-multiarch -x openocd.gdb"
# runner = "gdb -x openocd.gdb"
$ cargo run --example hello
(..)
Loading section .vector_table, size 0x400 lma 0x8000000
Loading section .text, size 0x1e70 lma 0x8000400
Loading section .rodata, size 0x61c lma 0x8002270
Start address 0x800144e, load size 10380
Transfer rate: 17 KB/sec, 3460 bytes/write.
(gdb)
Отображенные в память регистры
Встраиваемые системы могут зайти только так далеко, выполняя обычный код на Rust и перемещая данные в оперативной памяти. Если мы хотим получать информацию в систему или из нее (будь то мигание светодиода, обнаружение нажатия кнопки или взаимодействие с внешним периферийным устройством по какой-либо шине), нам придется погрузиться в мир периферийных устройств и их "отображенных в память регистров".
Вы можете обнаружить, что код, необходимый для доступа к периферийным устройствам вашего микроконтроллера, уже написан на одном из следующих уровней:

- Крейт микроархитектуры — этот тип крейта предоставляет полезные процедуры, общие для ядра процессора, используемого вашим микроконтроллером, а также любые периферийные устройства, общие для всех микроконтроллеров, использующих этот тип ядра процессора. Например, крейт cortex-m предоставляет функции для включения и отключения прерываний, которые одинаковы для всех микроконтроллеров на базе Cortex-M. Он также предоставляет доступ к периферийному устройству 'SysTick', включенному во все микроконтроллеры на базе Cortex-M.
- Крейт доступа к периферийным устройствам (PAC) — этот тип крейта представляет собой тонкую обертку над различными отображенными в память регистрами, определенными для конкретного номера детали вашего микроконтроллера. Например, tm4c123x для серии Texas Instruments Tiva-C TM4C123 или stm32f30x для серии ST-Micro STM32F30x. Здесь вы будете взаимодействовать с регистрами напрямую, следуя инструкциям по эксплуатации каждого периферийного устройства, приведенным в техническом справочном руководстве вашего микроконтроллера.
- Крейт HAL — эти крейты предлагают более удобный API для вашего конкретного процессора, часто реализуя общие трейты, определенные в embedded-hal. Например, этот крейт может предлагать структуру
Serialс конструктором, который принимает подходящий набор пинов GPIO и скорость передачи данных, и предоставляет функциюwrite_byteдля отправки данных.
Давайте рассмотрим пример:
#![no_std]
#![no_main]
use panic_halt as _; // Обработчик паники
use cortex_m_rt::entry;
use tm4c123x_hal as hal;
use tm4c123x_hal::prelude::*;
use tm4c123x_hal::serial::{NewlineMode, Serial};
use tm4c123x_hal::sysctl;
#[entry]
fn main() -> ! {
let p = hal::Peripherals::take().unwrap();
let cp = hal::CorePeripherals::take().unwrap();
// Обертывание структуры SYSCTL в объект с API более высокого уровня
let mut sc = p.SYSCTL.constrain();
// Выбор настроек осциллятора
sc.clock_setup.oscillator = sysctl::Oscillator::Main(
sysctl::CrystalFrequency::_16mhz,
sysctl::SystemClock::UsePll(sysctl::PllOutputFrequency::_80_00mhz),
);
// Настройка PLL с этими параметрами
let clocks = sc.clock_setup.freeze();
// Обертывание структуры GPIO_PORTA в объект с API более высокого уровня.
// Обратите внимание, что требуется заимствование `sc.power_control` для автоматического включения питания периферийного устройства GPIO
let mut porta = p.GPIO_PORTA.split(&sc.power_control);
// Активация UART.
let uart = Serial::uart0(
p.UART0,
// Пин передачи
porta
.pa1
.into_af_push_pull::<hal::gpio::AF1>(&mut porta.control),
// Пин приема
porta
.pa0
.into_af_push_pull::<hal::gpio::AF1>(&mut porta.control),
// RTS или CTS не требуются
(),
(),
// Скорость передачи данных
115200_u32.bps(),
// Обработка вывода
NewlineMode::SwapLFtoCRLF,
// Нам нужны частоты часов для расчета делителей скорости передачи
&clocks,
// Это необходимо для включения питания периферийного устройства UART
&sc.power_control,
);
loop {
writeln!(uart, "Hello, World!\r\n").unwrap();
}
}Семихостинг
Семихостинг — это механизм, который позволяет встраиваемым устройствам выполнять ввод/вывод на хосте и в основном используется для записи сообщений в консоль хоста. Семихостинг требует отладочной сессии и почти ничего больше (никаких дополнительных проводов!), поэтому его очень удобно использовать. Недостаток в том, что он очень медленный: каждая операция записи может занимать несколько миллисекунд в зависимости от используемого аппаратного отладчика (например, ST-Link).
Крейт cortex-m-semihosting предоставляет API для выполнения операций семихостинга на устройствах Cortex-M. Программа ниже — это версия "Hello, world!" с использованием семихостинга:
#![no_main]
#![no_std]
use panic_halt as _;
use cortex_m_rt::entry;
use cortex_m_semihosting::hprintln;
#[entry]
fn main() -> ! {
hprintln!("Hello, world!").unwrap();
loop {}
}Если вы запустите эту программу на оборудовании, вы увидите сообщение "Hello, world!" в логах OpenOCD.
$ openocd
(..)
Hello, world!
(..)
Вам нужно сначала включить семихостинг в OpenOCD из GDB:
(gdb) monitor arm semihosting enable
semihosting is enabled
QEMU понимает операции семихостинга, поэтому приведенная выше программа также будет работать с qemu-system-arm без необходимости запуска отладочной сессии. Обратите внимание, что вам нужно передать флаг -semihosting-config в QEMU для включения поддержки семихостинга; эти флаги уже включены в файл .cargo/config.toml шаблона.
$ # Эта программа заблокирует терминал
$ cargo run
Running `qemu-system-arm (..)
Hello, world!
Существует также операция семихостинга exit, которая может быть использована для завершения процесса QEMU. Важно: не используйте debug::exit на оборудовании; эта функция может повредить вашу сессию OpenOCD, и вы не сможете отлаживать другие программы, пока не перезапустите ее.
#![no_main]
#![no_std]
use panic_halt as _;
use cortex_m_rt::entry;
use cortex_m_semihosting::debug;
#[entry]
fn main() -> ! {
let roses = "blue";
if roses == "red" {
debug::exit(debug::EXIT_SUCCESS);
} else {
debug::exit(debug::EXIT_FAILURE);
}
loop {}
}$ cargo run
Running `qemu-system-arm (..)
$ echo $?
1
Один последний совет: вы можете настроить поведение паники на exit(EXIT_FAILURE). Это позволит вам писать тесты no_std с проверкой прохождения, которые можно запускать на QEMU.
Для удобства крейт panic-semihosting имеет функцию "exit", которая при включении вызывает exit(EXIT_FAILURE) после записи сообщения о панике в stderr хоста.
#![no_main]
#![no_std]
use panic_semihosting as _; // features = ["exit"]
use cortex_m_rt::entry;
use cortex_m_semihosting::debug;
#[entry]
fn main() -> ! {
let roses = "blue";
assert_eq!(roses, "red");
loop {}
}$ cargo run
Running `qemu-system-arm (..)
panicked at 'assertion failed: `(left == right)`
left: `"blue"`,
right: `"red"`', examples/hello.rs:15:5
$ echo $?
1
ПРИМЕЧАНИЕ: Чтобы включить эту функцию в panic-semihosting, отредактируйте раздел зависимостей в Cargo.toml, где указан panic-semihosting:
panic-semihosting = { version = "VERSION", features = ["exit"] }
где VERSION — желаемая версия. Для получения дополнительной информации о функциях зависимостей обратитесь к разделу указание зависимостей книги Cargo.
Паника
Паника — это основная часть языка Rust. Встроенные операции, такие как индексация, проверяются во время выполнения на предмет безопасности памяти. При попытке индексации за пределами границ массива возникает паника.
В стандартной библиотеке поведение паники определено: оно разворачивает стек вызывающего потока, если пользователь не выбрал завершение программы при панике.
Однако в программах без стандартной библиотеки поведение паники остается неопределенным. Поведение можно выбрать, объявив функцию #[panic_handler]. Эта функция должна появляться ровно один раз в графе зависимостей программы и иметь следующую сигнатуру: fn(&PanicInfo) -> !, где PanicInfo — это структура, содержащая информацию о месте возникновения паники.
Учитывая, что встраиваемые системы варьируются от пользовательских до критически важных для безопасности (не могут завершаться сбоем), не существует универсального поведения при панике, но есть множество часто используемых поведений. Эти общие поведения были упакованы в крейты, которые определяют функцию #[panic_handler]. Некоторые примеры включают:
panic-abort. Паника вызывает выполнение инструкции прерывания.panic-halt. Паника приводит к остановке программы или текущего потока в бесконечном цикле.panic-itm. Сообщение о панике записывается с использованием ITM, периферийного устройства, специфичного для ARM Cortex-M.panic-semihosting. Сообщение о панике отправляется на хост с использованием техники семихостинга.
Вы можете найти еще больше крейтов, выполнив поиск по ключевому слову panic-handler на crates.io.
Программа может выбрать одно из этих поведений, просто подключив соответствующий крейт...
#![no_main]
#![no_std]
// Профиль dev: упрощает отладку паник; можно установить точку останова на `rust_begin_unwind`
#[cfg(debug_assertions)]
use panic_halt as _;
// Профиль release: минимизирует размер бинарного файла приложения
#[cfg(not(debug_assertions))]
use panic_abort as _;
// ..В этом примере крейт подключается к panic-halt при сборке с профилем dev (cargo build), но к panic-abort при сборке с профилем release (cargo build --release).
Форма инструкции
use panic_abort as _;используется для обеспечения включения обработчика паникиpanic_abortв итоговый исполняемый файл, при этом ясно указывая компилятору, что мы не будем явно использовать что-либо из крейта. Без переименованияas _компилятор выдал бы предупреждение о неиспользуемом импорте. Иногда можно встретитьextern crate panic_abortвместо этого, что является старым стилем, использовавшимся до издания Rust 2018, и теперь должно использоваться только для "sysroot" крейтов (распространяемых вместе с Rust), таких какproc_macro,alloc,stdиtest.
Пример
Вот пример, который пытается индексировать массив за его пределами. Эта операция приводит к панике.
#![no_main]
#![no_std]
use panic_semihosting as _;
use cortex_m_rt::entry;
#[entry]
fn main() -> ! {
let xs = [0, 1, 2];
let i = xs.len();
let _y = xs[i]; // Доступ за пределами массива
loop {}
}В этом примере выбрано поведение panic-semihosting, которое выводит сообщение о панике на консоль хоста с использованием семихостинга.
$ cargo run
Running `qemu-system-arm -cpu cortex-m3 -machine lm3s6965evb (..)
panicked at 'index out of bounds: the len is 3 but the index is 4', src/main.rs:12:13
Вы можете попробовать изменить поведение на panic-halt и убедиться, что в этом случае сообщение не выводится.
Исключения
Исключения и прерывания — это аппаратный механизм, с помощью которого процессор обрабатывает асинхронные события и фатальные ошибки (например, выполнение недопустимой инструкции). Исключения подразумевают вытеснение и включают обработчики исключений — подпрограммы, выполняемые в ответ на сигнал, вызвавший событие.
Крейт cortex-m-rt предоставляет атрибут exception для объявления обработчиков исключений.
// Обработчик исключения для исключения SysTick (системный таймер)
#[exception]
fn SysTick() {
// ..
}Помимо атрибута exception, обработчики исключений выглядят как обычные функции, но есть одно важное различие: обработчики exception нельзя вызывать программно. Например, в приведенном выше примере вызов SysTick(); приведет к ошибке компиляции.
Такое поведение намеренное и необходимо для обеспечения следующей особенности: переменные static mut, объявленные внутри обработчиков exception, безопасны для использования.
#[exception]
fn SysTick() {
static mut COUNT: u32 = 0;
// `COUNT` преобразуется в тип `&mut u32` и безопасен для использования
*COUNT += 1;
}Как известно, использование переменных static mut в функции делает ее нереентерабельной. Вызов нереентерабельной функции, прямо или косвенно, из нескольких обработчиков исключений/прерываний или из main и одного или более обработчиков исключений/прерываний приводит к неопределенному поведению.
Безопасный Rust никогда не должен приводить к неопределенному поведению, поэтому нереентерабельные функции должны быть помечены как unsafe. Однако, как было сказано, обработчики exception могут безопасно использовать переменные static mut. Это возможно, потому что обработчики exception не могут быть вызваны программно, что исключает возможность реентерабельности. Эти обработчики вызываются самим аппаратным обеспечением...
ПРИМЕЧАНИЕ: Этот программный код не будет работать (т.е. не завершится сбоем) на QEMU, поскольку
qemu-system-arm -machine lm3s6965evbне проверяет загрузку памяти и с радостью вернет0при чтении из недопустимой памяти.
#![no_main]
#![no_std]
use panic_halt as _;
use core::fmt::Write;
use core::ptr;
use cortex_m_rt::{entry, exception, ExceptionFrame};
use cortex_m_semihosting::hio;
#[entry]
fn main() -> ! {
// Чтение из несуществующего адреса памяти
unsafe {
ptr::read_volatile(0x3FFF_0000 as *const u32);
}
loop {}
}
#[exception]
fn HardFault(ef: &ExceptionFrame) -> ! {
if let Ok(mut hstdout) = hio::hstdout() {
writeln!(hstdout, "{:#?}", ef).ok();
}
loop {}
}Обработчик HardFault выводит значение ExceptionFrame. Если вы запустите этот код, вы увидите что-то вроде этого в консоли OpenOCD:
$ openocd
(..)
ExceptionFrame {
r0: 0x3fff0000,
r1: 0x00000003,
r2: 0x080032e8,
r3: 0x00000000,
r12: 0x00000000,
lr: 0x080016df,
pc: 0x080016e2,
xpsr: 0x61000000,
}
Значение pc — это значение программного счетчика на момент исключения, и оно указывает на инструкцию, вызвавшую исключение.
Если посмотреть дизассемблированный код программы:
$ cargo objdump --bin app --release -- -d --no-show-raw-insn --print-imm-hex
(..)
ResetTrampoline:
8000942: movw r0, #0xfffe
8000946: movt r0, #0x3fff
800094a: ldr r0, [r0]
800094c: b #-0x4 <ResetTrampoline+0xa>
Вы можете найти значение программного счетчика 0x0800094a в дизассемблированном коде. Вы увидите, что операция загрузки (ldr r0, [r0]) вызвала исключение. Поле r0 в ExceptionFrame покажет, что значение регистра r0 в этот момент было 0x3fff_fffe.
Прерывания
Прерывания отличаются от исключений по ряду параметров, но их работа и использование в основном схожи, и они обрабатываются одним и тем же контроллером прерываний. В то время как исключения определяются архитектурой Cortex-M, прерывания всегда являются специфичными для производителя (и часто даже для конкретной микросхемы) как по именованию, так и по функциональности.
Прерывания предоставляют большую гибкость, которую необходимо учитывать при их использовании в сложных сценариях. В этой книге мы не будем рассматривать такие случаи, но важно помнить следующее:
- Прерывания имеют программируемые приоритеты, которые определяют порядок выполнения их обработчиков.
- Прерывания могут быть вложенными и вытеснять друг друга, т.е. выполнение обработчика прерывания может быть прервано другим прерыванием с более высоким приоритетом.
- В общем случае причину, вызвавшую прерывание, необходимо устранить, чтобы предотвратить бесконечное повторное вхождение в обработчик прерывания.
Общие шаги инициализации во время выполнения всегда одинаковы:
- Настройка периферийных устройств для генерации запросов на прерывания в нужных случаях.
- Установка желаемого приоритета обработчика прерывания в контроллере прерываний.
- Включение обработчика прерывания в контроллере прерываний.
Аналогично исключениям, крейт cortex-m-rt предоставляет атрибут interrupt для объявления обработчиков прерываний. Однако этот атрибут доступен только при включении функции устройства. При этом данный атрибут не предназначен для прямого использования — это приведет к ошибке компиляции.
Вместо этого вы должны использовать переэкспортированную версию атрибута interrupt, предоставляемую крейтом устройства (обычно сгенерированным с помощью svd2rust). Это гарантирует, что компилятор может проверить, существует ли прерывание на целевом устройстве. Список доступных прерываний — и их положение в таблице векторов прерываний — обычно автоматически генерируется из файла SVD с помощью svd2rust.
use lm3s6965::interrupt; // Переэкспортированный атрибут из крейта устройства
// Обработчик прерывания для прерывания Timer2
#[interrupt]
fn TIMER2A() {
// ..
// Устранение причины, вызвавшей запрос на прерывание
}Обработчики прерываний выглядят как обычные функции (за исключением отсутствия аргументов), подобно обработчикам исключений. Однако их нельзя вызывать напрямую другими частями прошивки из-за специальных соглашений о вызове. Тем не менее, можно программно генерировать запросы на прерывания, чтобы вызвать переход к обработчику прерывания.
Подобно обработчикам исключений, в обработчиках прерываний также можно безопасно объявлять переменные static mut для хранения состояния.
#[interrupt]
fn TIMER2A() {
static mut COUNT: u32 = 0;
// `COUNT` имеет тип `&mut u32` и безопасен для использования
*COUNT += 1;
}Для более подробного описания механизмов, продемонстрированных здесь, обратитесь к [разделу об исключениях].
Ввод/вывод
TODO Рассмотреть отображение ввода/вывода в память с использованием регистров.
Периферийные устройства
Что такое периферийные устройства?
Большинство микроконтроллеров имеют не только процессор, оперативную память или флэш-память — они содержат участки кремния, которые используются для взаимодействия с системами вне микроконтроллера, а также для прямого и косвенного взаимодействия с окружающим миром через датчики, контроллеры двигателей или интерфейсы для человека, такие как дисплей или клавиатура. Эти компоненты в совокупности называются периферийными устройствами.
Эти периферийные устройства полезны, потому что позволяют разработчику переложить обработку на них, избегая необходимости обрабатывать все в программном обеспечении. Подобно тому, как разработчик настольных приложений перекладывает обработку графики на видеокарту, разработчики встраиваемых систем могут переложить некоторые задачи на периферийные устройства, позволяя процессору заниматься чем-то другим важным или вообще ничего не делать, чтобы сэкономить энергию.
Если посмотреть на основную печатную плату старомодного домашнего компьютера 1970-х или 1980-х годов (а на самом деле настольные ПК прошлого не так уж далеки от современных встраиваемых систем), вы ожидаете увидеть:
- Процессор
- Чип оперативной памяти
- Чип ПЗУ
- Контроллер ввода-вывода
Чип оперативной памяти, чип ПЗУ и контроллер ввода-вывода (периферийное устройство в этой системе) будут соединены с процессором через серию параллельных дорожек, известных как "шина". Эта шина передает адресную информацию, которая выбирает, с каким устройством на шине процессор хочет взаимодействовать, и шину данных, которая передает фактические данные. В наших встраиваемых микроконтроллерах применяются те же принципы — просто все упаковано на одном куске кремния.
Однако, в отличие от видеокарт, которые обычно имеют программный API, такой как Vulkan, Metal или OpenGL, периферийные устройства в микроконтроллерах представлены через аппаратный интерфейс, который отображается на участок памяти.
Линейное и реальное адресное пространство
На микроконтроллере запись данных по произвольному адресу, например 0x4000_0000 или 0x0000_0000, может быть полностью корректной операцией.
На настольной системе доступ к памяти строго контролируется MMU (Memory Management Unit, блок управления памятью). Этот компонент выполняет две основные функции: обеспечение доступа...
На микроконтроллере адресное пространство используется иначе. Например, как упоминалось в предыдущих главах, оперативная память может быть расположена по адресу 0x2000_0000. Если наша оперативная память имеет размер 64 КиБ (т.е. максимальный адрес 0x2000_FFFF), то адреса от 0x2000_0000 до 0x2000_FFFF будут соответствовать нашей оперативной памяти. Когда мы записываем в переменную, находящуюся по адресу 0x2000_1234, внутри происходит логика, которая определяет верхнюю часть адреса (в данном случае 0x2000) и активирует оперативную память, чтобы она могла работать с нижней частью адреса (0x1234 в данном случае). На Cortex-M у нас также есть флэш-ПЗУ, отображенное по адресу 0x0000_0000 до, скажем, адреса 0x0007_FFFF (если у нас флэш-ПЗУ на 512 КиБ). Вместо того чтобы игнорировать все оставшееся пространство между этими двумя областями, разработчики микроконтроллеров отобразили интерфейс для периферийных устройств на определенные адреса памяти. Это выглядит примерно так:
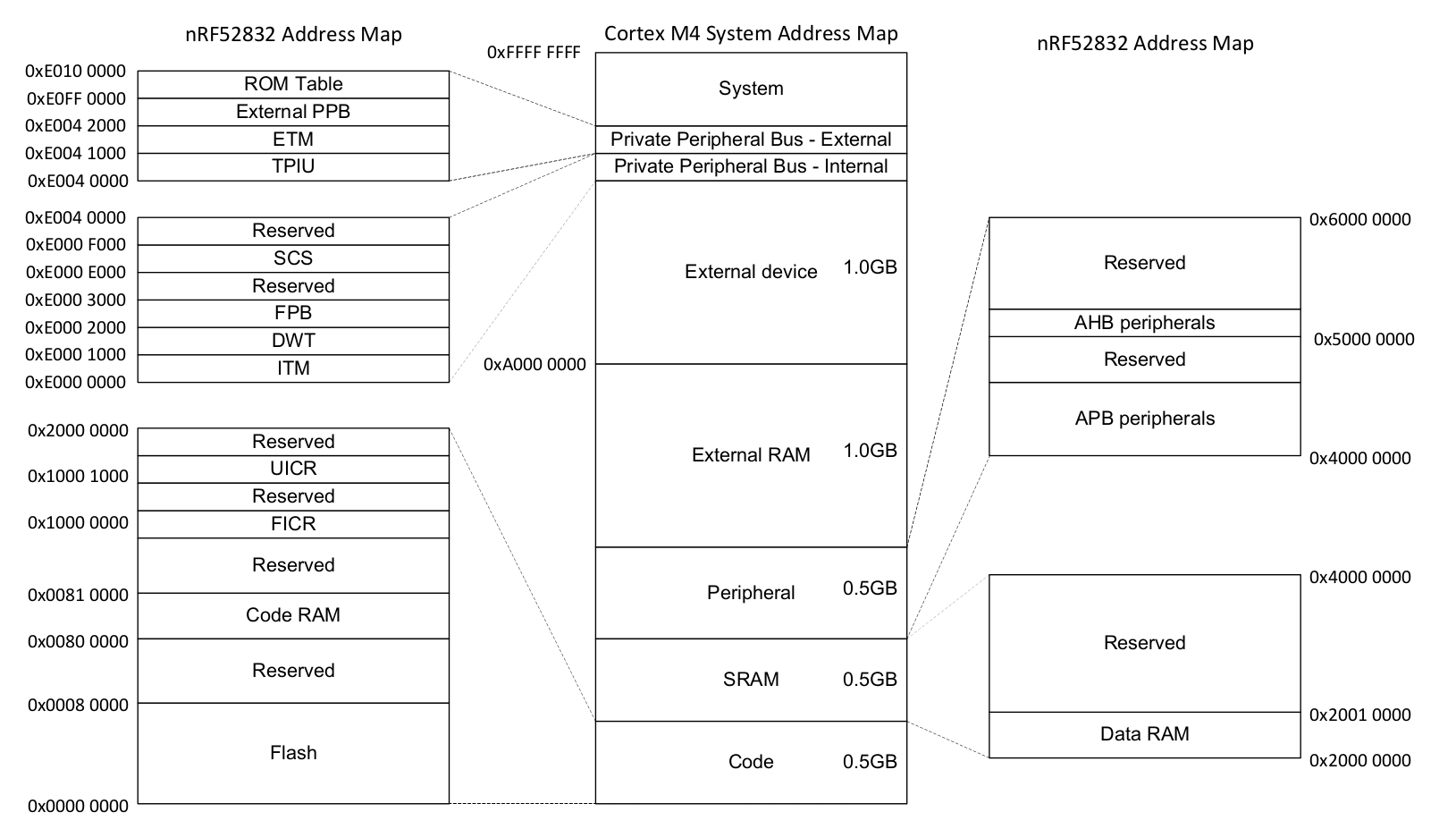
Техническое описание Nordic nRF52832 (pdf)
Отображенные в память периферийные устройства
Взаимодействие с этими периферийными устройствами на первый взгляд кажется простым — запишите правильные данные по правильному адресу. Например, отправка 32-битного слова через последовательный порт может быть настолько же простой, как запись этого 32-битного слова по определенному адресу памяти. Периферийное устройство последовательного порта затем возьмет на себя задачу и автоматически отправит данные.
Конфигурация этих периферийных устройств работает аналогично. Вместо вызова функции для настройки периферийного устройства предоставляется участок памяти, который служит аппаратным API. Запишите 0x8000_0000 в регистр конфигурации частоты SPI, и порт SPI будет отправлять данные со скоростью 8 мегабит в секунду. Запишите 0x0200_0000 по тому же адресу, и порт SPI будет отправлять данные со скоростью 125 килобит в секунду. Эти регистры конфигурации выглядят примерно так:

Техническое описание Nordic nRF52832 (pdf)
Этот интерфейс — способ взаимодействия с аппаратным обеспечением, независимо от используемого языка, будь то ассемблер, C или Rust.
Первая попытка
Регистры
Рассмотрим периферийное устройство 'SysTick' — простой таймер, который поставляется с каждым процессорным ядром Cortex-M. Обычно вы ищете информацию об этом в техническом описании микросхемы или Справочном руководстве, но данный пример общий для всех ядер ARM Cortex-M, поэтому обратимся к [Справочному руководству ARM]. Мы видим, что есть четыре регистра:
| Смещение | Имя | Описание | Ширина |
|---|---|---|---|
| 0x00 | SYST_CSR | Регистр управления и состояния | 32 бита |
| 0x04 | SYST_RVR | Регистр значения перезагрузки | 32 бита |
| 0x08 | SYST_CVR | Регистр текущего значения | 32 бита |
| 0x0C | SYST_CALIB | Регистр значения калибровки | 32 бита |
Подход на C
В Rust мы можем представить набор регистров точно так же, как в C — с помощью struct.
#[repr(C)]
struct SysTick {
pub csr: u32,
pub rvr: u32,
pub cvr: u32,
pub calib: u32,
}Квалификатор #[repr(C)] указывает компилятору Rust размещать эту структуру так, как это сделал бы компилятор C. Это очень важно, так как Rust позволяет переупорядочивать поля структуры, а C — нет. Представьте, какой отладкой нам пришлось бы заниматься, если бы эти поля были тихо переупорядочены компилятором! С этим квалификатором у нас есть четыре 32-битных поля, соответствующих приведенной выше таблице. Но, конечно, сама по себе эта struct бесполезна — нам нужна переменная.
let systick = 0xE000_E010 as *mut SysTick;
let time = unsafe { (*systick).cvr };Волатильные доступы
В приведенном выше подходе есть несколько проблем.
- Нам приходится использовать
unsafeкаждый раз, когда мы хотим получить доступ к нашему периферийному устройству. - У нас нет способа указать, какие регистры предназначены только для чтения, а какие — для чтения и записи.
Чтобы решить эти проблемы, мы можем использовать крейт volatile-register, который предоставляет типы RO (только для чтения), WO (только для записи) и RW (чтение/запись). Это позволяет нам определить, какие операции безопасны, и избежать случайной записи в регистр только для чтения.
Кроме того, нам нужно использовать волатильные операции для доступа к памяти, чтобы гарантировать, что компилятор не оптимизирует наши операции чтения или записи. Это достигается с помощью методов read и write из крейта volatile-register.
Обертка в стиле Rust
Нам нужно обернуть эту struct в API более высокого уровня, который безопасен для вызова пользователями. Как автор драйвера, мы вручную проверяем, что небезопасный код корректен, а затем предоставляем безопасный API для пользователей, чтобы они не беспокоились об этом (при условии, что они доверяют нам, что мы сделали это правильно!).
Пример может выглядеть так:
use volatile_register::{RW, RO};
pub struct SystemTimer {
p: &'static mut RegisterBlock
}
#[repr(C)]
struct RegisterBlock {
pub csr: RW<u32>,
pub rvr: RW<u32>,
pub cvr: RW<u32>,
pub calib: RO<u32>,
}
impl SystemTimer {
pub fn new() -> SystemTimer {
SystemTimer {
p: unsafe { &mut *(0xE000_E010 as *mut RegisterBlock) }
}
}
pub fn get_time(&self) -> u32 {
self.p.cvr.read()
}
pub fn set_reload(&mut self, reload_value: u32) {
unsafe { self.p.rvr.write(reload_value) }
}
}
pub fn example_usage() -> String {
let mut st = SystemTimer::new();
st.set_reload(0x00FF_FFFF);
format!("Time is now 0x{:08x}", st.get_time())
}Теперь проблема в том, что следующий код полностью приемлем для компилятора:
fn thread1() {
let mut st = SystemTimer::new();
st.set_reload(2000);
}
fn thread2() {
let mut st = SystemTimer::new();
st.set_reload(1000);
}Наш аргумент &mut self в функции set_reload проверяет, что нет других ссылок на этот конкретный экземпляр структуры SystemTimer, но он не мешает пользователю создать второй экземпляр SystemTimer, который указывает на то же самое периферийное устройство! Код, написанный в таком стиле, будет работать, если автор достаточно внимателен, чтобы заметить все эти "дублирующиеся" экземпляры драйвера, но как только код распространяется по нескольким модулям, драйверам, разработчикам и дням, такие ошибки становятся все проще совершать.
Изменяемое глобальное состояние
К сожалению, аппаратное обеспечение — это, по сути, не что иное, как изменяемое глобальное состояние, что может пугать разработчика на Rust. Аппаратное обеспечение существует независимо от структур кода, который мы пишем, и может быть изменено в любой момент реальным миром.
Какими должны быть наши правила?
Как мы можем надежно взаимодействовать с этими периферийными устройствами?
- Всегда используйте методы
volatileдля чтения или записи в память периферийных устройств, так как она может измениться в любой момент. - В программном обеспечении мы должны иметь возможность предоставлять любое количество доступов только для чтения к этим периферийным устройствам.
- Если программное обеспечение должно иметь доступ на чтение и запись к периферийному устройству, оно должно быть единственным обладателем ссылки на это устройство.
Проверяющий заимствования
Последние два правила подозрительно похожи на то, что уже делает проверяющий заимствования (Borrow Checker)!
Представьте, если бы мы могли передавать владение этими периферийными устройствами или предоставлять неизменяемые или изменяемые ссылки на них?
Мы можем это сделать, но для проверяющего заимствования нам нужно иметь ровно один экземпляр каждого периферийного устройства, чтобы Rust мог корректно это обработать. К счастью, в аппаратном обеспечении есть только один экземпляр любого данного периферийного устройства, но как мы можем отразить это в структуре нашего кода?
Синглтоны
В программной инженерии шаблон синглтон — это шаблон проектирования, который ограничивает создание экземпляров класса одним объектом.
Википедия: Шаблон синглтон
Почему нельзя просто использовать глобальные переменные?
Мы могли бы сделать все публичными статическими переменными, например так:
static mut THE_SERIAL_PORT: SerialPort = SerialPort;
fn main() {
let _ = unsafe {
THE_SERIAL_PORT.read_speed();
};
}Но у этого подхода есть несколько проблем. Это изменяемая глобальная переменная, и в Rust взаимодействие с такими переменными всегда небезопасно. Кроме того, эти переменные видны во всей программе, что означает, что проверяющий заимствования не может помочь вам отслеживать ссылки и владение этими переменными.
Как это сделать в Rust?
Вместо того чтобы делать наше периферийное устройство глобальной переменной, мы можем создать структуру, в данном случае названную PERIPHERALS, которая содержит Option<T> для каждого из наших периферийных устройств.
struct Peripherals {
serial: Option<SerialPort>,
}
impl Peripherals {
fn take_serial(&mut self) -> SerialPort {
let p = replace(&mut self.serial, None);
p.unwrap()
}
}
static mut PERIPHERALS: Peripherals = Peripherals {
serial: Some(SerialPort),
};Эта структура позволяет нам получить единственный экземпляр нашего периферийного устройства. Если мы попытаемся вызвать take_serial() более одного раза, наш код вызовет панику!
fn main() {
let serial_1 = unsafe { PERIPHERALS.take_serial() };
// Это вызовет панику!
// let serial_2 = unsafe { PERIPHERALS.take_serial() };
}Хотя взаимодействие с этой структурой является unsafe, после того как мы получили содержащийся в ней SerialPort, нам больше не нужно использовать unsafe или саму структуру PERIPHERALS.
Это имеет небольшую накладную стоимость во время выполнения, поскольку нам нужно обернуть структуру SerialPort в Option, и нам придется один раз вызвать take_serial(), однако эта небольшая начальная стоимость позволяет нам использовать проверяющий заимствования...
#[entry]
fn main(cx: main::Context) -> ! {
// Получение доступа к периферийным устройствам ядра
let core: CorePeripherals = cx.core;
// Устройство-специфичные периферийные устройства
let device: lm3s6965::Peripherals = cx.device;
}Но зачем?
Но как эти синглтоны существенно влияют на работу нашего кода на Rust?
impl SerialPort {
const SER_PORT_SPEED_REG: *mut u32 = 0x4000_1000 as _;
fn read_speed(
&self // <------ Это действительно очень важно
) -> u32 {
unsafe {
ptr::read_volatile(Self::SER_PORT_SPEED_REG)
}
}
}Здесь действуют два важных фактора:
- Поскольку мы используем синглтон, есть только один способ или место для получения структуры
SerialPort. - Чтобы вызвать метод
read_speed(), мы должны иметь владение или ссылку на структуруSerialPort.
Эти два фактора вместе означают, что доступ к аппаратному обеспечению возможен только в том случае, если мы соответствующим образом удовлетворили проверяющий заимствования, что означает, что у нас никогда не будет нескольких изменяемых ссылок на одно и то же аппаратное обеспечение!
fn main() {
// Отсутствует ссылка на `self`! Не сработает.
// SerialPort::read_speed();
let serial_1 = unsafe { PERIPHERALS.take_serial() };
// Вы можете читать только то, к чему у вас есть доступ
let _ = serial_1.read_speed();
}Относитесь к вашему оборудованию как к данным
Кроме того, поскольку некоторые ссылки изменяемые, а некоторые — неизменяемые, становится возможным определить, может ли функция или метод потенциально изменить состояние аппаратного обеспечения. Например,
Это может изменять настройки оборудования:
fn setup_spi_port(
spi: &mut SpiPort,
cs_pin: &mut GpioPin
) -> Result<()> {
// ...
}А это — нет:
fn read_button(gpio: &GpioPin) -> bool {
// ...
}Это позволяет нам обеспечивать, будет ли код изменять аппаратное обеспечение или нет, на этапе компиляции, а не во время выполнения. Заметьте, что это обычно работает только в пределах одного приложения, но для систем без операционной системы наше программное обеспечение компилируется в одно приложение, так что это обычно не является ограничением.
Статические гарантии
Система типов Rust предотвращает гонки данных на этапе компиляции (см. трейты Send и Sync). Система типов также может использоваться для проверки других свойств на этапе компиляции, уменьшая необходимость проверок во время выполнения в некоторых случаях.
При применении к встраиваемым программам эти статические проверки могут использоваться, например, для обеспечения правильной конфигурации интерфейсов ввода-вывода. Например, можно разработать API, в котором инициализация последовательного интерфейса возможна только после предварительной настройки пинов, которые будут использоваться этим интерфейсом.
Также можно статически проверять, что такие операции, как установка пина в низкий уровень, могут выполняться только на правильно сконфигурированных периферийных устройствах. Например, попытка изменить состояние выхода пина, настроенного в режиме плавающего входа, вызовет ошибку компиляции.
И, как было показано в предыдущей главе, концепция владения может быть применена к периферийным устройствам, чтобы гарантировать, что только определенные части программы могут изменять периферийное устройство. Этот контроль доступа делает программное обеспечение более предсказуемым по сравнению с альтернативой, когда периферийные устройства рассматриваются как глобальное изменяемое состояние.
Программирование с типовыми состояниями
Концепция [типовых состояний] описывает кодирование информации о текущем состоянии объекта в тип этого объекта. Хотя это может звучать немного загадочно, если вы использовали шаблон Builder в Rust, вы уже начали использовать программирование с типовыми состояниями!
pub mod foo_module { #[derive(Debug)] pub struct Foo { inner: u32, } pub struct FooBuilder { a: u32, b: u32, } impl FooBuilder { pub fn new(starter: u32) -> Self { Self { a: starter, b: starter, } } pub fn double_a(self) -> Self { Self { a: self.a * 2, b: self.b, } } pub fn into_foo(self) -> Foo { Foo { inner: self.a + self.b, } } } } fn main() { let x = foo_module::FooBuilder::new(10) .double_a() .into_foo(); println!("{:#?}", x); }
В этом примере нет прямого способа создать объект Foo. Мы должны создать FooBuilder и правильно его инициализировать, прежде чем сможем получить желаемый объект Foo.
Этот минимальный пример кодирует два состояния:
FooBuilder, который представляет состояние "неконфигурировано" или "конфигурация в процессе".Foo, который представляет состояние "сконфигурировано" или "готово к использованию".
Сильная типизация
Поскольку Rust имеет [сильную систему типов], нет простого способа магически создать экземпляр Foo или превратить FooBuilder в Foo без вызова метода into_foo(). Кроме того, вызов метода into_foo() потребляет исходную структуру FooBuilder, что означает, что ее нельзя повторно использовать без создания нового экземпляра.
Это позволяет нам представлять состояния нашей системы как типы и включать необходимые действия для переходов между состояниями в методы, которые обменивают один тип на другой. Создавая FooBuilder и обменивая его на объект Foo, мы проходим через шаги простого конечного автомата.
Периферийные устройства как конечные автоматы
Периферийные устройства микроконтроллера можно рассматривать как набор конечных автоматов. Например, конфигурация упрощенного [GPIO-пина] может быть представлена следующим деревом состояний:
- Отключен
- Включен
- Настроен как выход
- Выход: Высокий
- Выход: Низкий
- Настроен как вход
- Вход: Высокое сопротивление
- Вход: Подтяжка вниз
- Вход: Подтяжка вверх
- Настроен как выход
Если периферийное устройство начинается в режиме Отключен, для перехода в режим Вход: Высокое сопротивление необходимо выполнить следующие шаги:
- Отключен
- Включен
- Настроен как вход
- Вход: Высокое сопротивление
Если мы хотим перейти из Вход: Высокое сопротивление в Вход: Подтяжка вниз, необходимо выполнить следующие шаги:
- Вход: Высокое сопротивление
- Вход: Подтяжка вниз
Аналогично, если мы хотим перевести GPIO-пин из режима Вход: Подтяжка вниз в Выход: Высокий, необходимо выполнить следующие шаги:
- Вход: Подтяжка вниз
- Настроен как вход
- Настроен как выход
- Выход: Высокий
Аппаратное представление
Обычно перечисленные выше состояния устанавливаются путем записи значений в заданные регистры, отображенные на периферийное устройство GPIO. Давайте определим воображаемый регистр конфигурации GPIO для иллюстрации:
| Имя | Бит(ы) | Значение | Значение | Примечания |
|---|---|---|---|---|
| enable | 0 | 0 | отключено | Отключает GPIO |
| 1 | включено | Включает GPIO | ||
| direction | 1 | 0 | вход | Устанавливает направление на вход |
| 1 | выход | Устанавливает направление на выход | ||
| input_mode | 2..3 | 00 | высокое сопротивление | Устанавливает вход как высокое сопротивление |
| 01 | подтяжка вниз | Входной пин подтянут вниз | ||
| 10 | подтяжка вверх | Входной пин подтянут вверх | ||
| 11 | н/д | Недопустимое состояние. Не устанавливать | ||
| output_mode | 4 | 0 | установить низкий | Выходной пин притянут к низкому уровню |
| 1 | установить высокий | Выходной пин притянут к высокому уровню | ||
| input_status | 5 | x | входное значение | 0, если вход < 1.5 В, 1, если вход >= 1.5 В |
Мы могли бы предоставить следующую структуру в Rust для управления этим GPIO:
/// Интерфейс GPIO
struct GpioConfig {
/// Структура конфигурации GPIO, сгенерированная svd2rust
periph: GPIO_CONFIG,
}
impl GpioConfig {
pub fn set_enable(&mut self, is_enabled: bool) {
self.periph.modify(|_r, w| {
w.enable().set_bit(is_enabled)
});
}
pub fn set_direction(&mut self, is_output: bool) {
self.periph.modify(|_r, w| {
w.direction().set_bit(is_output)
});
}
pub fn set_input_mode(&mut self, variant: InputMode) {
self.periph.modify(|_r, w| {
w.input_mode().variant(variant)
});
}
pub fn set_output_mode(&mut self, is_high: bool) {
self.periph.modify(|_r, w| {
w.output_mode.set_bit(is_high)
});
}
pub fn get_input_status(&self) -> bool {
self.periph.read().input_status().bit_is_set()
}
}Однако это позволило бы нам изменять определенные регистры, что не имеет смысла. Например, что произойдет, если мы установим поле output_mode, когда наш GPIO настроен как вход?
В общем, использование этой структуры позволило бы нам достичь состояний, не определенных в нашем конечном автомате выше: например, выход, который подтянут вниз, или вход, который установлен на высокий уровень. Для некоторого оборудования это может не иметь значения. На другом оборудовании это может вызвать неожиданное или неопределенное поведение!
Хотя этот интерфейс удобен для написания, он не обеспечивает соблюдение контрактов проектирования, установленных нашей аппаратной реализацией.
Контракты проектирования
В предыдущей главе мы создали интерфейс, который не обеспечивал соблюдение контрактов проектирования. Давайте еще раз посмотрим на наш воображаемый регистр конфигурации GPIO:
| Имя | Бит(ы) | Значение | Значение | Примечания |
|---|---|---|---|---|
| enable | 0 | 0 | отключено | Отключает GPIO |
| 1 | включено | Включает GPIO | ||
| direction | 1 | 0 | вход | Устанавливает направление на вход |
| 1 | выход | Устанавливает направление на выход | ||
| input_mode | 2..3 | 00 | высокое сопротивление | Устанавливает вход как высокое сопротивление |
| 01 | подтяжка вниз | Входной пин подтянут вниз | ||
| 10 | подтяжка вверх | Входной пин подтянут вверх | ||
| 11 | н/д | Недопустимое состояние. Не устанавливать | ||
| output_mode | 4 | 0 | установить низкий | Выходной пин притянут к низкому уровню |
| 1 | установить высокий | Выходной пин притянут к высокому уровню | ||
| input_status | 5 | x | входное значение | 0, если вход < 1.5 В, 1, если вход >= 1.5 В |
Если вместо этого мы проверяли бы состояние перед использованием базового оборудования, обеспечивая соблюдение наших контрактов проектирования во время выполнения, мы могли бы написать код, который выглядит следующим образом:
/// Интерфейс GPIO
struct GpioConfig {
/// Структура конфигурации GPIO, сгенерированная svd2rust
periph: GPIO_CONFIG,
}
impl GpioConfig {
pub fn set_enable(&mut self, is_enabled: bool) {
self.periph.modify(|_r, w| {
w.enable().set_bit(is_enabled)
});
}
pub fn set_direction(&mut self, is_output: bool) -> Result<(), ()> {
if self.periph.read().enable().bit_is_clear() {
// Для установки направления пин должен быть включен
return Err(());
}
self.periph.modify(|r, w| {
w.direction().set_bit(is_output)
});
Ok(())
}
pub fn set_input_mode(&mut self, variant: InputMode) -> Result<(), ()> {
if self.periph.read().enable().bit_is_clear() {
// Для установки режима входа пин должен быть включен
return Err(());
}
if self.periph.read().direction().bit_is_set() {
// Для установки режима входа направление должно быть входным
return Err(());
}
self.periph.modify(|_r, w| {
w.input_mode().variant(variant)
});
Ok(())
}
pub fn set_output_mode(&mut self, is_high: bool) -> Result<(), ()> {
if self.periph.read().enable().bit_is_clear() {
// Для установки режима выхода пин должен быть включен
return Err(());
}
if self.periph.read().direction().bit_is_clear() {
// Для установки режима выхода направление должно быть выходным
return Err(());
}
self.periph.modify(|_r, w| {
w.output_mode().set_bit(is_high)
});
Ok(())
}
pub fn get_input_status(&self) -> bool {
self.periph.read().input_status().bit_is_set()
}
}Теперь давайте используем типовые состояния для кодирования этих состояний в типах, чтобы обеспечить соблюдение контрактов проектирования на этапе компиляции:
struct Enabled;
struct Disabled;
struct Input;
struct Output;
struct HighZ;
struct PulledLow;
struct PulledHigh;
struct GpioConfig<E, D, M> {
periph: GPIO_CONFIG,
enabled: E,
direction: D,
mode: M,
}
impl GpioConfig<Disabled, Input, HighZ> {
pub fn new(periph: GPIO_CONFIG) -> Self {
GpioConfig {
periph,
enabled: Disabled,
direction: Input,
mode: HighZ,
}
}
pub fn into_enabled_input(self) -> GpioConfig<Enabled, Input, HighZ> {
self.periph.modify(|_r, w| w.enable().set_bit(true));
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Input,
mode: HighZ,
}
}
}
impl GpioConfig<Enabled, Input, HighZ> {
pub fn bit_is_set(&self) -> bool {
self.periph.read().input_status().bit_is_set()
}
pub fn into_enabled_output(self) -> GpioConfig<Enabled, Output, PulledHigh> {
self.periph.modify(|_r, w| w.direction().set_bit(true));
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Output,
mode: PulledHigh,
}
}
pub fn into_input_pull_down(self) -> GpioConfig<Enabled, Input, PulledLow> {
self.periph.modify(|_r, w| w.input_mode().pull_low());
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Input,
mode: PulledLow,
}
}
pub fn into_input_pull_up(self) -> GpioConfig<Enabled, Input, PulledHigh> {
self.periph.modify(|_r, w| w.input_mode().pull_high());
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Input,
mode: PulledHigh,
}
}
}
impl GpioConfig<Enabled, Input, PulledLow> {
pub fn bit_is_set(&self) -> bool {
self.periph.read().input_status().bit_is_set()
}
pub fn into_enabled_output(self) -> GpioConfig<Enabled, Output, PulledHigh> {
self.periph.modify(|_r, w| w.direction().set_bit(true));
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Output,
mode: PulledHigh,
}
}
pub fn into_input_pull_up(self) -> GpioConfig<Enabled, Input, PulledHigh> {
self.periph.modify(|_r, w| w.input_mode().pull_high());
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Input,
mode: PulledHigh,
}
}
}Теперь давайте посмотрим, как будет выглядеть код, использующий это:
/*
* Пример 1: Из неконфигурированного в вход с высоким сопротивлением
*/
let pin: GpioConfig<Disabled, _, _> = get_gpio();
// Нельзя сделать это, пин не включен!
// pin.into_input_pull_down();
// Теперь переводим пин из неконфигурированного во вход с высоким сопротивлением
let input_pin = pin.into_enabled_input();
// Чтение с пина
let pin_state = input_pin.bit_is_set();
// Нельзя сделать это, входные пины не имеют этого интерфейса!
// input_pin.set_bit(true);
/*
* Пример 2: Из входа с высоким сопротивлением во вход с подтяжкой вниз
*/
let pulled_low = input_pin.into_input_pull_down();
let pin_state = pulled_low.bit_is_set();
/*
* Пример 3: Из входа с подтяжкой вниз в выход, установленный на высокий уровень
*/
let output_pin = pulled_low.into_enabled_output();
output_pin.set_bit(true);
// Нельзя сделать это, выходные пины не имеют этого интерфейса!
// output_pin.into_input_pull_down();Этот способ определенно удобен для хранения состояния пина, но почему стоит делать это именно так? Почему это лучше, чем хранить состояние в виде enum внутри структуры GpioConfig?
Функциональная безопасность на этапе компиляции
Поскольку мы обеспечиваем соблюдение наших проектных ограничений полностью на этапе компиляции, это не влечет затрат во время выполнения. Невозможно установить режим вывода, когда пин находится в режиме ввода. Вместо этого вы должны пройти через состояния, сначала преобразовав его в выходной пин, а затем установив режим вывода. Благодаря этому отсутствует штраф за проверку текущего состояния перед выполнением функции во время выполнения.
Кроме того, поскольку эти состояния обеспечиваются системой типов, для пользователей этого интерфейса больше нет места для ошибок. Если они попытаются выполнить недопустимый переход состояния, код просто не скомпилируется!
Абстракции с нулевой стоимостью
Типовые состояния также являются отличным примером абстракций с нулевой стоимостью — способности переносить определенные поведения на этап компиляции или анализа. Эти типовые состояния не содержат фактических данных и вместо этого используются как маркеры. Поскольку они не содержат данных, у них нет фактического представления в памяти во время выполнения:
use core::mem::size_of;
let _ = size_of::<Enabled>(); // == 0
let _ = size_of::<Input>(); // == 0
let _ = size_of::<PulledHigh>(); // == 0
let _ = size_of::<GpioConfig<Enabled, Input, PulledHigh>>(); // == 0Типы нулевого размера
struct Enabled;Структуры, определенные таким образом, называются типами нулевого размера, поскольку они не содержат фактических данных. Хотя эти типы ведут себя как "настоящие" на этапе компиляции — их можно копировать, перемещать, брать ссылки на них и т.д., оптимизатор полностью удаляет их.
В этом фрагменте кода:
pub fn into_input_high_z(self) -> GpioConfig<Enabled, Input, HighZ> {
self.periph.modify(|_r, w| w.input_mode().high_z());
GpioConfig {
periph: self.periph,
enabled: Enabled,
direction: Input,
mode: HighZ,
}
}Возвращаемая структура GpioConfig никогда не существует во время выполнения. Вызов этой функции обычно сводится к одной инструкции на ассемблере — записи константного значения регистра в адрес регистра. Это означает, что разработанный нами интерфейс типовых состояний является абстракцией с нулевой стоимостью — он не использует больше процессорного времени, оперативной памяти или пространства для кода для отслеживания состояния GpioConfig и преобразуется в тот же машинный код, что и прямой доступ к регистру.
Вложение
В общем, эти абстракции могут быть вложены так глубоко, как вы пожелаете. Пока все используемые компоненты являются типами нулевого размера, вся структура не будет существовать во время выполнения.
Для сложных или глубоко вложенных структур определение всех возможных комбинаций состояний может быть утомительным. В таких случаях можно использовать макросы для генерации всех реализаций.
Портируемость
Встраиваемые системы делают портируемость очень важной темой: каждый производитель и даже каждая серия от одного производителя предлагает различные периферийные устройства и возможности, а способы взаимодействия с этими периферийными устройствами также различаются.
Общий способ устранения таких различий — использование слоя, называемого уровнем абстракции оборудования или HAL.
Абстракции оборудования — это наборы программных процедур, которые эмулируют некоторые специфические для платформы детали, предоставляя программам прямой доступ к аппаратным ресурсам.
Они часто позволяют программистам писать независимые от устройства высокопроизводительные приложения, предоставляя стандартные вызовы операционной системы к оборудованию.
Википедия: Уровень абстракции оборудования
Встраиваемые системы в этом отношении немного особенные, поскольку обычно у них нет операционных систем и программного обеспечения, устанавливаемого пользователем, а вместо этого используются образы прошивки, которые компилируются целиком, а также существуют другие ограничения. Таким образом, традиционный подход, определенный Википедией, потенциально может работать, но, вероятно, не является наиболее продуктивным для обеспечения портируемости.
Как это делается в Rust? Встречайте embedded-hal...
Что такое embedded-hal?
Вкратце, это набор трейтов, которые определяют контракты реализации между реализациями HAL, драйверами и приложениями (или прошивками). Эти контракты включают как возможности (т.е. если трейт реализован для определенного типа, реализация HAL предоставляет определенную функциональность), так и методы (т.е. если вы можете создать тип, реализующий трейт, гарантируется наличие методов, указанных в этом трейте).
Типичная структура уровней может выглядеть следующим образом:

Некоторые из определенных трейтов в embedded-hal включают:
- GPIO (пины ввода и вывода)
- Последовательная связь
- I2C
- SPI
- Таймеры/обратные отсчеты
- Аналогово-цифровое преобразование
Основная причина использования трейтов embedded-hal и крейтов, их реализующих и использующих, — это контроль сложности. Если учесть, что приложение должно реализовать использование периферийного устройства в оборудовании, а также само приложение и, возможно, драйверы для дополнительных аппаратных компонентов, становится понятно, что возможности повторного использования весьма ограничены. Математически, если M — это количество реализаций HAL для периферийных устройств, а N — количество драйверов, то без использования embedded-hal сложность реализации может достигать M×N. Использование трейтов embedded-hal снижает сложность реализации до уровня, близкого к M+N. Конечно, есть и дополнительные преимущества, такие как меньшее количество проб и ошибок благодаря хорошо определенным и готовым к использованию API.
Пользователи embedded-hal
Как упомянуто выше, есть три основных пользователя HAL:
Реализация HAL
Реализация HAL обеспечивает взаимодействие между оборудованием и пользователями трейтов HAL. Типичные реализации состоят из трех частей:
- Один или несколько типов, специфичных для оборудования
- Функции для создания и инициализации таких типов, часто предоставляющие различные параметры конфигурации (скорость, режим работы, используемые пины и т.д.)
- Одна или несколько реализаций (
impl) трейтов embedded-hal для этого типа
Такая реализация HAL может быть представлена в различных вариантах:
- Через низкоуровневый доступ к оборудованию, например, через регистры
- Через операционную систему, например, с использованием
sysfsв Linux - Через адаптер, например, заглушки типов для модульного тестирования
- Через драйвер для аппаратных адаптеров, например, мультиплексор I2C или расширитель GPIO
Драйвер
Драйвер реализует набор пользовательских функций для внутреннего или внешнего компонента, подключенного к периферийному устройству, реализующему трейты embedded-hal. Типичные примеры таких драйверов включают различные датчики (температуры, магнитометр, акселерометр, освещенности), устройства отображения (светодиодные матрицы, ЖК-дисплеи) и исполнительные механизмы (двигатели, передатчики).
Драйвер должен быть инициализирован экземпляром типа, реализующего определенный трейт embedded-hal, что обеспечивается через ограничение трейта, и предоставляет собственный экземпляр типа с пользовательским набором методов, позволяющих взаимодействовать с управляемым устройством.
Приложение
Приложение объединяет различные части и обеспечивает достижение желаемой функциональности. При переносе между различными системами именно эта часть требует наибольших усилий по адаптации, поскольку приложение должно правильно инициализировать реальное оборудование через реализацию HAL, а инициализация различного оборудования может существенно отличаться. Кроме того, выбор пользователя часто играет большую роль, поскольку компоненты могут быть физически подключены к разным терминалам, шины оборудования иногда требуют внешнего оборудования для соответствия конфигурации, или существуют различные компромиссы в использовании внутренних периферийных устройств (например, доступно несколько таймеров с разными возможностями, или периферийные устройства конфликтуют друг с другом).
Параллелизм
Параллелизм возникает, когда разные части вашей программы могут выполняться в разное время или не по порядку. В контексте встраиваемых систем это включает:
- Обработчики прерываний, которые запускаются при возникновении соответствующего прерывания.
- Различные формы многопоточности, когда микропроцессор регулярно переключается между частями вашей программы.
- В некоторых системах — многоядерные микропроцессоры, где каждое ядро может независимо выполнять разные части программы одновременно.
Поскольку многие программы для встраиваемых систем должны работать с прерываниями, вопросы параллелизма возникают рано или поздно, и именно здесь могут появляться тонкие и сложные ошибки. К счастью, Rust предоставляет ряд абстракций и гарантий безопасности, которые помогают писать корректный код.
Отсутствие параллелизма
Самый простой подход к параллелизму в программе для встраиваемых систем — это его полное отсутствие: программа состоит из одного основного цикла, который непрерывно выполняется, и прерывания полностью отсутствуют. Иногда это идеально подходит для решаемой задачи! Обычно такой цикл считывает входные данные, выполняет их обработку и записывает выходные данные.
#[entry]
fn main() {
let peripherals = setup_peripherals();
loop {
let inputs = read_inputs(&peripherals);
let outputs = process(inputs);
write_outputs(&peripherals, outputs);
}
}Поскольку параллелизм отсутствует, нет необходимости беспокоиться о совместном использовании данных между частями программы или синхронизации доступа к периферийным устройствам. Если такой простой подход подходит для вашей задачи, это может быть отличным решением.
Глобальные изменяемые данные
В отличие от Rust для не-встраиваемых систем, мы обычно не можем позволить себе создавать выделения памяти на куче и передавать ссылки на эти данные в новые потоки. Вместо этого обработчики прерываний могут быть вызваны в любой момент и должны знать, как получить доступ к общей памяти. На самом низком уровне это означает, что у нас должна быть статически выделенная изменяемая память, на которую могут ссылаться как обработчик прерываний, так и основной код.
В Rust такие переменные static mut всегда небезопасны для чтения или записи, так как без особых мер предосторожности можно вызвать состояние гонки, когда доступ к переменной прерывается на полпути прерыванием, которое также обращается к этой переменной.
Для примера, как это поведение может вызывать тонкие ошибки, рассмотрим программу для встраиваемых систем, которая подсчитывает восходящие фронты входного сигнала за каждый односекундный период (счетчик частоты):
static mut COUNTER: u32 = 0;
#[entry]
fn main() -> ! {
set_timer_1hz();
let mut last_state = false;
loop {
let state = read_signal_level();
if state && !last_state {
// ОПАСНОСТЬ - На самом деле не безопасно! Может вызвать гонки данных.
unsafe { COUNTER += 1 };
}
last_state = state;
}
}
#[interrupt]
fn timer() {
unsafe { COUNTER = 0; }
}Каждую секунду прерывание таймера сбрасывает счетчик в 0. Тем временем основной цикл непрерывно измеряет сигнал и увеличивает счетчик при обнаружении перехода с низкого уровня на высокий. Нам пришлось использовать unsafe для доступа к COUNTER, так как это static mut, что означает, что мы обещаем компилятору не вызывать неопределенное поведение. Можете ли вы заметить состояние гонки? Операция увеличения COUNTER не гарантированно атомарна — на большинстве платформ для встраиваемых систем она будет разделена на загрузку, увеличение и сохранение. Если прерывание сработает после загрузки, но до сохранения, сброс в 0 будет проигнорирован после возврата из прерывания — и мы подсчитаем в два раза больше переходов за этот период.
Критические секции
Как справиться с гонками данных? Простой подход — использовать критические секции, контекст, в котором прерывания отключены. Обернув доступ к COUNTER в main в критическую секцию, мы можем быть уверены, что прерывание таймера не сработает, пока мы не закончим увеличение COUNTER:
static mut COUNTER: u32 = 0;
#[entry]
fn main() -> ! {
set_timer_1hz();
let mut last_state = false;
loop {
let state = read_signal_level();
if state && !last_state {
// Новая критическая секция обеспечивает синхронизированный доступ к COUNTER
cortex_m::interrupt::free(|_| {
unsafe { COUNTER += 1 };
});
}
last_state = state;
}
}
#[interrupt]
fn timer() {
unsafe { COUNTER = 0; }
}В этом примере мы используем cortex_m::interrupt::free, но на других платформах будут аналогичные механизмы для выполнения кода в критической секции. Это эквивалентно отключению прерываний, выполнению кода и последующему их включению.
Обратите внимание, что критическая секция не понадобилась внутри прерывания таймера по двум причинам:
- Запись 0 в
COUNTERне может быть затронута гонкой, так как мы не читаем его. - Прерывание в любом случае не будет прервано основным потоком.
Если COUNTER разделяется между несколькими обработчиками прерываний, которые могут вытеснять друг друга, то для каждого из них также может потребоваться критическая секция.
Этот подход решает нашу проблему, но мы по-прежнему пишем много небезопасного кода, о котором нужно тщательно рассуждать, и можем использовать критические секции без необходимости. Каждая критическая секция временно приостанавливает обработку прерываний, что увеличивает размер кода, задержку и джиттер прерываний (прерывания могут обрабатываться дольше, и время до их обработки становится более переменным). Является ли это проблемой, зависит от вашей системы, но в целом мы хотели бы этого избежать.
Важно отметить, что критическая секция гарантирует отсутствие срабатывания прерываний, но не обеспечивает гарантии эксклюзивности в многоядерных системах! Другое ядро может одновременно обращаться к той же памяти, даже без прерываний. Для многоядерных систем потребуются более мощные примитивы синхронизации.
Атомарный доступ
На некоторых платформах доступны специальные атомарные инструкции, которые обеспечивают гарантии для операций чтения-модификации-записи. В частности, для Cortex-M: thumbv6 (Cortex-M0, Cortex-M0+) поддерживает только атомарные инструкции загрузки и сохранения, тогда как thumbv7 (Cortex-M3 и выше) предоставляет полные инструкции Compare and Swap (CAS). Эти инструкции CAS являются альтернативой полному отключению прерываний: мы можем попытаться выполнить увеличение, которое в большинстве случаев успешно, но если оно прерывается, операция увеличения автоматически повторяется. Эти атомарные операции безопасны даже в многоядерных системах.
use core::sync::atomic::{AtomicUsize, Ordering};
static COUNTER: AtomicUsize = AtomicUsize::new(0);
#[entry]
fn main() -> ! {
set_timer_1hz();
let mut last_state = false;
loop {
let state = read_signal_level();
if state && !last_state {
// Используем `fetch_add` для атомарного добавления 1 к COUNTER
COUNTER.fetch_add(1, Ordering::Relaxed);
}
last_state = state;
}
}
#[interrupt]
fn timer() {
// Используем `store` для прямой записи 0 в COUNTER
COUNTER.store(0, Ordering::Relaxed);
}Теперь COUNTER — это безопасная static переменная. Благодаря типу AtomicUsize переменная COUNTER может быть безопасно модифицирована как из обработчика прерываний, так и из основного потока без отключения прерываний. Использование Ordering::Relaxed минимизирует накладные расходы на синхронизацию, так как в данном случае не требуется строгая упорядоченность операций между потоками.
Доступ к периферийным устройствам
В дополнение к общим данным программы часто требуется разделять доступ к периферийным устройствам между основным потоком и обработчиками прерываний. Например, мы можем захотеть считывать входной сигнал с пина GPIO в основном цикле и управлять выходным сигналом с того же порта GPIO в обработчике прерываний.
Типичная проблема в embedded-программах заключается в том, что периферийные устройства являются синглтонами: существует только один экземпляр каждого периферийного устройства. В Rust это часто моделируется с помощью метода take(), который возвращает Option и позволяет захватить периферийное устройство в момент выполнения программы. Чтобы безопасно разделять доступ к такому синглтону, мы можем использовать Mutex и RefCell из библиотеки cortex_m для обеспечения синхронизированного доступа в критических секциях.
use core::cell::RefCell;
use cortex_m::interrupt::{self, Mutex};
use stm32f4::stm32f405;
static MY_GPIO: Mutex<RefCell<Option<stm32f405::GPIOA>>> =
Mutex::new(RefCell::new(None));
#[entry]
fn main() -> ! {
// Получаем синглтоны периферийных устройств и настраиваем их.
// Этот пример использует крейт, сгенерированный svd2rust, но
// большинство крейтов для встраиваемых устройств будут похожими.
let dp = stm32f405::Peripherals::take().unwrap();
let gpioa = &dp.GPIOA;
// Некоторая функция настройки.
// Предположим, она устанавливает PA0 как вход и PA1 как выход.
configure_gpio(gpioa);
// Сохраняем GPIOA в мьютекс, перемещая его.
interrupt::free(|cs| MY_GPIO.borrow(cs).replace(Some(dp.GPIOA)));
// Теперь мы больше не можем использовать `gpioa` или `dp.GPIOA`, и должны
// обращаться к нему через мьютекс.
// Будьте осторожны, включая прерывание только после настройки MY_GPIO:
// иначе прерывание может сработать, пока MY_GPIO содержит None,
// и в текущей реализации (с `unwrap()`) это вызовет панику.
set_timer_1hz();
let mut last_state = false;
loop {
// Теперь мы будем считывать состояние как цифровой вход через мьютекс
let state = interrupt::free(|cs| {
let gpioa = MY_GPIO.borrow(cs).borrow();
gpioa.as_ref().unwrap().idr.read().idr0().bit_is_set()
});
if state && !last_state {
// Устанавливаем PA1 в высокий уровень, если обнаружен восходящий фронт на PA0.
interrupt::free(|cs| {
let gpioa = MY_GPIO.borrow(cs).borrow();
gpioa.as_ref().unwrap().odr.modify(|_, w| w.odr1().set_bit());
});
}
last_state = state;
}
}
#[interrupt]
fn timer() {
// В прерывании мы просто сбрасываем PA0.
interrupt::free(|cs| {
// Мы можем использовать `unwrap()`, потому что знаем, что прерывание
// не было включено до установки MY_GPIO; в противном случае нужно
// обрабатывать возможность значения None.
let gpioa = MY_GPIO.borrow(cs).borrow();
gpioa.as_ref().unwrap().odr.modify(|_, w| w.odr1().clear_bit());
});
}Это довольно объемный код, поэтому разберем ключевые моменты.
static MY_GPIO: Mutex<RefCell<Option<stm32f405::GPIOA>>> =
Mutex::new(RefCell::new(None));Наша общая переменная — это Mutex, содержащий RefCell, который в свою очередь содержит Option. Mutex обеспечивает доступ только в критической секции, что делает переменную безопасной для синхронизации (Sync), хотя обычный RefCell не является Sync. RefCell предоставляет внутреннюю изменяемость через ссылки, что необходимо для работы с GPIOA. Option позволяет инициализировать переменную пустым значением и позже переместить в нее фактическое значение. Мы не можем получить доступ к синглтону периферийного устройства статически, только во время выполнения, поэтому это необходимо.
interrupt::free(|cs| MY_GPIO.borrow(cs).replace(Some(dp.GPIOA)));Внутри критической секции мы вызываем borrow() на мьютексе, что дает нам ссылку на RefCell. Затем мы вызываем replace(), чтобы переместить новое значение в RefCell.
interrupt::free(|cs| {
let gpioa = MY_GPIO.borrow(cs).borrow();
gpioa.as_ref().unwrap().odr.modify(|_, w| w.odr1().set_bit());
});Наконец, мы используем MY_GPIO безопасно и параллельно. Критическая секция предотвращает срабатывание прерывания, как обычно, и позволяет нам заимствовать мьютекс. RefCell дает нам &Option<GPIOA> и отслеживает, как долго он остается заимствованным — после выхода ссылки из области видимости RefCell обновляется, указывая, что он больше не заимствован.
Поскольку мы не можем переместить GPIOA из &Option, нам нужно преобразовать его в &Option<&GPIOA> с помощью as_ref(), который мы затем можем unwrap(), чтобы получить &GPIOA, позволяющий модифицировать периферийное устройство.
Если требуется изменяемая ссылка на общий ресурс, следует использовать borrow_mut и deref_mut. Следующий код показывает пример с использованием таймера TIM2.
use core::cell::RefCell;
use core::ops::DerefMut;
use cortex_m::interrupt::{self, Mutex};
use cortex_m::asm::wfi;
use stm32f4::stm32f405;
static G_TIM: Mutex<RefCell<Option<Timer<stm32f4::stm32f405::TIM2>>>> =
Mutex::new(RefCell::new(None));
#[entry]
fn main() -> ! {
let mut cp = cortex_m::Peripherals::take().unwrap();
let dp = stm32f4::stm32f405::Peripherals::take().unwrap();
// Некоторая функция настройки таймера.
// Предположим, она настраивает таймер TIM2, его прерывание NVIC
// и запускает таймер.
let tim = configure_timer_interrupt(&mut cp, dp);
interrupt::free(|cs| {
G_TIM.borrow(cs).replace(Some(tim));
});
loop {
wfi();
}
}
#[interrupt]
fn timer() {
interrupt::free(|cs| {
if let Some(ref mut tim) = G_TIM.borrow(cs).borrow_mut().deref_mut() {
tim.start(1.hz());
}
});
}Это безопасно, но немного громоздко. Есть ли другие варианты?
RTIC
Одной из альтернатив является фреймворк RTIC, сокращение от Real Time Interrupt-driven Concurrency (Параллелизм, управляемый прерываниями реального времени). Он обеспечивает статические приоритеты и отслеживает доступ к переменным static mut (называемым "ресурсами"), чтобы статически гарантировать безопасный доступ к общим ресурсам без необходимости постоянного входа в критические секции и использования подсчета ссылок (как в RefCell). Это дает ряд преимуществ, таких как отсутствие тупиков и чрезвычайно низкие затраты по времени и памяти.
Фреймворк также включает другие функции, такие как передача сообщений, что уменьшает необходимость в явном общем состоянии, и возможность планировать задачи для выполнения в определенное время, что можно использовать для реализации периодических задач. Подробности см. в документации.
Операционные системы реального времени
Еще одна распространенная модель для параллелизма во встраиваемых системах — операционные системы реального времени (RTOS). Хотя в Rust они пока менее исследованы, они широко используются в традиционной разработке для встраиваемых систем. Примеры с открытым исходным кодом включают FreeRTOS и ChibiOS. Эти RTOS предоставляют поддержку выполнения нескольких потоков приложения, между которыми процессор переключается, либо когда потоки уступают управление (кооперативная многозадачность), либо на основе регулярного таймера или прерываний (вытесняющая многозадачность). RTOS обычно предоставляют мьютексы и другие примитивы синхронизации и часто взаимодействуют с аппаратными функциями, такими как движки DMA.
На момент написания мало примеров RTOS на Rust, но это интересная область, так что следите за обновлениями!
Многоядерные системы
Наличие двух или более ядер в процессорах для встраиваемых систем становится все более распространенным, что добавляет дополнительный уровень сложности к параллелизму. Все примеры с использованием критических секций (включая cortex_m::interrupt::Mutex) предполагают, что единственный другой поток выполнения — это поток прерываний, но в многоядерной системе это уже не так. Вместо этого потребуются примитивы синхронизации, разработанные для многоядерных систем (также называемых SMP, симметричная многопроцессорность).
Они обычно используют атомарные инструкции, которые мы видели ранее, поскольку система обработки гарантирует сохранение атомарности на всех ядрах.
Подробное рассмотрение этих тем пока выходит за рамки этой книги, но общие шаблоны аналогичны случаю с одним ядром.
Коллекции
В конечном итоге вы захотите использовать динамические структуры данных (также известные как коллекции) в вашей программе. std предоставляет набор общих коллекций: Vec, String, HashMap и т.д. Все коллекции, реализованные в std, используют глобальный динамический распределитель памяти (также известный как куча).
Поскольку core по определению свободен от выделения памяти, эти реализации недоступны там, но их можно найти в крейте alloc, поставляемом с компилятором.
Если вам нужны коллекции, реализация с выделением на куче — не единственный вариант. Вы также можете использовать коллекции с фиксированной емкостью; одна такая реализация находится в крейте heapless.
В этом разделе мы рассмотрим и сравним эти две реализации.
Использование alloc
Крейт alloc поставляется со стандартной дистрибуцией Rust. Чтобы импортировать крейт, вы можете напрямую use его без объявления как зависимости в вашем файле Cargo.toml.
#![feature(alloc)]
extern crate alloc;
use alloc::vec::Vec;Чтобы использовать любую коллекцию, вам сначала нужно использовать атрибут global_allocator для объявления глобального распределителя, который будет использовать ваша программа. Требуется, чтобы выбранный распределитель реализовывал трейт GlobalAlloc.
Для полноты и чтобы сделать этот раздел как можно более самодостаточным, мы реализуем простой распределитель указателя смещения и используем его как глобальный распределитель. Однако мы настоятельно рекомендуем использовать проверенный в боях распределитель из crates.io в вашей программе вместо этого распределителя.
// Реализация распределителя указателя смещения
use core::alloc::{GlobalAlloc, Layout};
use core::cell::UnsafeCell;
use core::ptr;
use cortex_m::interrupt;
// Распределитель указателя смещения для *одноядерных* систем
struct BumpPointerAlloc {
head: UnsafeCell<usize>,
end: usize,
}
unsafe impl Sync for BumpPointerAlloc {}
unsafe impl GlobalAlloc for BumpPointerAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
// `interrupt::free` — это критическая секция, которая делает наш распределитель безопасным
// для использования внутри прерываний
interrupt::free(|_| {
let head = self.head.get();
let size = layout.size();
let align = layout.align();
let align_mask = !(align - 1);
// перемещаем начало к следующей границе выравнивания
let start = (*head + align - 1) & align_mask;
if start + size > self.end {
// нулевой указатель сигнализирует об условии Out Of Memory
ptr::null_mut()
} else {
*head = start + size;
start as *mut u8
}
})
}
unsafe fn dealloc(&self, _: *mut u8, _: Layout) {
// этот распределитель никогда не освобождает память
}
}
// Объявление глобального распределителя памяти
// ПРИМЕЧАНИЕ: пользователь должен убедиться, что область памяти `[0x2000_0100, 0x2000_0200]`
// не используется другими частями программы
#[global_allocator]
static HEAP: BumpPointerAlloc = BumpPointerAlloc {
head: UnsafeCell::new(0x2000_0100),
end: 0x2000_0200,
};Помимо выбора глобального распределителя, пользователь также должен определить, как обрабатываются ошибки Out Of Memory (OOM), используя нестабильный атрибут alloc_error_handler.
#![feature(alloc_error_handler)]
use cortex_m::asm;
#[alloc_error_handler]
fn on_oom(_layout: Layout) -> ! {
asm::bkpt();
loop {}
}После того, как все это на месте, пользователь наконец-то может использовать коллекции в alloc.
#[entry]
fn main() -> ! {
let mut xs = Vec::new();
xs.push(42);
assert!(xs.pop(), Some(42));
loop {
// ..
}
}Если вы использовали коллекции в крейте std, то эти будут знакомы, поскольку это точно такая же реализация.
Использование heapless
heapless не требует настройки, поскольку его коллекции не зависят от глобального распределителя памяти. Просто use его коллекции и приступайте к ихインスタции:
// версия heapless: v0.4.x
use heapless::Vec;
use heapless::consts::*;
#[entry]
fn main() -> ! {
let mut xs: Vec<_, U8> = Vec::new();
xs.push(42).unwrap();
assert_eq!(xs.pop(), Some(42));
loop {}
}Вы заметите две разницы между этими коллекциями и теми, что в alloc.
Во-первых, вы должны объявить заранее емкость коллекции. Коллекции heapless никогда не перераспределяются и имеют фиксированные емкости; эта емкость является частью сигнатуры типа коллекции. В этом случае мы объявили, что xs имеет емкость 8 элементов, то есть вектор может содержать максимум 8 элементов. Это указано U8 (см. typenum) в сигнатуре типа.
Во-вторых, метод push и многие другие методы возвращают Result. Поскольку коллекции heapless имеют фиксированную емкость, все операции, вставляющие элементы в коллекцию, потенциально могут завершиться неудачей. API отражает эту проблему, возвращая Result, указывающий, удалась ли операция. В отличие от этого, коллекции alloc перераспределят себя на куче, чтобы увеличить емкость.
Начиная с версии v0.4.x, все коллекции heapless хранят все свои элементы inline. Это означает, что операция вроде let x = heapless::Vec::new(); выделит коллекцию на стеке, но также возможно выделить коллекцию в static переменной или даже на куче (Box<Vec<_, _>>).
Компромиссы
Учитывайте эти аспекты при выборе между коллекциями с выделением на куче, перемещаемыми, и коллекциями с фиксированной емкостью.
Out Of Memory и обработка ошибок
С выделением на куче Out Of Memory всегда возможен и может возникнуть в любом месте, где коллекция может нуждаться в росте: например, все вызовы alloc::Vec.push потенциально могут генерировать условие OOM. Таким образом, некоторые операции могут неявно завершаться неудачей. Некоторые коллекции alloc предоставляют методы try_reserve, которые позволяют проверить потенциальные условия OOM при росте коллекции, но вы должны быть proactive в их использовании.
Если вы исключительно используете коллекции heapless и не используете распределитель памяти ни для чего другого, то условие OOM невозможно. Вместо этого вам придется справляться с исчерпанием емкости коллекций на основе случая за случаем. То есть вам придется справляться со всеми Result, возвращаемыми методами вроде Vec.push.
Сбои OOM могут быть сложнее отлаживать, чем, скажем, unwrap на всех Result, возвращаемых heapless::Vec.push, потому что наблюдаемое место сбоя может не совпадать с местом причины проблемы. Например, даже vec.reserve(1) может вызвать OOM, если распределитель почти исчерпан, потому что какая-то другая коллекция протекала память (утечки памяти возможны в безопасном Rust).
Использование памяти
Рассуждения об использовании памяти коллекций с выделением на куче сложны, потому что емкость долгоживущих коллекций может изменяться во время выполнения. Некоторые операции могут неявно перераспределять коллекцию, увеличивая использование памяти, и некоторые коллекции предоставляют методы вроде shrink_to_fit, которые потенциально могут уменьшить память, используемую коллекцией — в конечном итоге, распределитель решает, действительно ли сжимать выделение памяти или нет. Кроме того, распределитель может сталкиваться с фрагментацией памяти, что может увеличивать видимое использование памяти.
С другой стороны, если вы исключительно используете коллекции с фиксированной емкостью, храните большинство из них в static переменных и устанавливаете максимальный размер стека вызовов, то линкер обнаружит, если вы пытаетесь использовать больше памяти, чем физически доступно.
Кроме того, коллекции с фиксированной емкостью, выделенные на стеке, будут сообщены флагом -Z emit-stack-sizes, что означает, что инструменты, анализирующие использование стека (вроде stack-sizes), включат их в свой анализ.
Однако коллекции с фиксированной емкостью не могут быть уменьшены, что может привести к более низким коэффициентам загрузки (соотношение между размером коллекции и ее емкостью), чем то, чего могут достичь перемещаемые коллекции.
Худшее время выполнения (WCET)
Если вы строите приложения, чувствительные ко времени, или приложения реального времени с жесткими требованиями, то вы заботитесь, возможно, сильно, о худшем времени выполнения различных частей вашей программы.
Коллекции alloc могут перераспределяться, так что WCET операций, которые могут расти коллекцию, также будет включать время, затрачиваемое на перераспределение коллекции, которое само зависит от времени выполнения емкости коллекции. Это делает сложным определение WCET, например, операции alloc::Vec.push, поскольку оно зависит как от используемого распределителя, так и от его емкости во время выполнения.
С другой стороны, коллекции с фиксированной емкостью никогда не перераспределяются, так что все операции имеют предсказуемое время выполнения. Например, heapless::Vec.push выполняется за постоянное время.
Простота использования
alloc требует настройки глобального распределителя, в то время как heapless нет. Однако heapless требует, чтобы вы выбирали емкость каждойインスタциируемой коллекции.
API alloc будет знаком практически каждому разработчику на Rust. API heapless пытается тесно имитировать API alloc, но никогда не будет точно таким же из-за явной обработки ошибок — некоторые разработчики могут считать явную обработку ошибок чрезмерной или слишком громоздкой.
Шаблоны проектирования
Эта глава стремится собрать различные полезные шаблоны проектирования для embedded Rust.
Шаблоны проектирования HAL
Это набор общих и рекомендуемых шаблонов для написания уровней аппаратной абстракции (HAL) для микроконтроллеров на Rust. Эти шаблоны предназначены для использования в дополнение к существующим Рекомендациям по API Rust при написании HAL для микроконтроллеров.
Контрольный список шаблонов проектирования HAL
- Именование (крейт соответствует соглашениям об именовании в Rust)
- Крейт назван правильно (C-CRATE-NAME)
- Взаимодействие (крейт хорошо взаимодействует с функциональностью других библиотек)
- Типы-обертки предоставляют метод деструктора (C-FREE)
- HAL переэкспортируют свой крейт доступа к регистрам (C-REEXPORT-PAC)
-
Типы реализуют трейты
embedded-hal(C-HAL-TRAITS)
- Предсказуемость (крейт позволяет писать читаемый код, который работает так, как выглядит)
- Используются конструкторы вместо трейтов расширения (C-CTOR)
- Интерфейсы GPIO (Интерфейсы GPIO следуют общему шаблону)
- Типы пинов по умолчанию нулевого размера (C-ZST-PIN)
- Типы пинов предоставляют методы для стирания пина и порта (C-ERASED-PIN)
- Состояние пина должно быть закодировано как параметры типа (C-PIN-STATE)
Именование
Крейт назван корректно (C-CRATE-NAME)
Крейты HAL должны быть названы по имени микросхемы или семейства микросхем, которые они поддерживают. Их имя должно заканчиваться на -hal, чтобы отличать их от крейтов доступа к регистрам. В имени не должны использоваться подчеркивания (вместо них используйте дефисы).
Интероперабельность
Типы-обертки предоставляют метод деструктора (C-FREE)
Любой тип-обертка, не являющийся Copy, предоставляемый HAL, должен иметь метод free, который потребляет обертку и возвращает исходное периферийное устройство (и, возможно, другие объекты), из которого она была создана.
Метод должен при необходимости выключать и сбрасывать периферийное устройство. Вызов new с исходным периферийным устройством, возвращенным из free, не должен завершаться с ошибкой из-за неожиданного состояния периферийного устройства.
Если тип HAL требует создания других объектов, не являющихся Copy (например, пинов ввода-вывода), такие объекты также должны быть освобождены и возвращены методом free. В этом случае free должен возвращать кортеж.
Пример:
#![allow(unused)] fn main() { pub struct TIMER0; pub struct Timer(TIMER0); impl Timer { pub fn new(periph: TIMER0) -> Self { Self(periph) } pub fn free(self) -> TIMER0 { self.0 } } }
HAL переэкспортирует свой крейт доступа к регистрам (C-REEXPORT-PAC)
HAL могут быть написаны на основе PAC, сгенерированных svd2rust, или на основе других крейтов, предоставляющих прямой доступ к регистрам. HAL всегда должны переэкспортировать крейт доступа к регистрам, на котором они основаны, в корне своего крейта.
PAC должен быть переэкспортирован под именем pac, независимо от фактического имени крейта, поскольку имя HAL уже должно ясно указывать, какой PAC используется.
Типы реализуют трейты embedded-hal (C-HAL-TRAITS)
Типы, предоставляемые HAL, должны реализовывать все применимые трейты, предоставляемые крейтом embedded-hal.
Один и тот же тип может реализовывать несколько трейтов.
Предсказуемость
Используются конструкторы вместо трейтов-расширений (C-CTOR)
Все периферийные устройства, для которых HAL добавляет функциональность, должны быть обернуты в новый тип, даже если для этой функциональности не требуются дополнительные поля.
Следует избегать реализации трейтов-расширений для исходного периферийного устройства.
Методы помечены #[inline] там, где это уместно (C-INLINE)
Компилятор Rust по умолчанию не выполняет полное встраивание через границы крейтов. Поскольку приложения для встраиваемых систем чувствительны к неожиданным увеличениям размера кода, #[inline] следует использовать для направления компилятора следующим образом:
- Все "маленькие" функции должны быть помечены
#[inline]. Что считать "маленьким" — субъективно, но, как правило, все функции, которые компилируются в последовательности инструкций с однозначным количеством, считаются маленькими. - Функции, которые с высокой вероятностью принимают константные значения в качестве параметров, должны быть помечены
#[inline]. Это позволяет компилятору вычислять даже сложную логику инициализации во время компиляции, если входные данные функции известны.
Рекомендации для интерфейсов GPIO
Типы пинов по умолчанию имеют нулевой размер (C-ZST-PIN)
Интерфейсы GPIO, предоставляемые HAL, должны предоставлять выделенные типы нулевого размера для каждого пина на каждом интерфейсе или порте, обеспечивая абстракцию GPIO с нулевыми накладными расходами, когда все назначения пинов статически известны.
Каждый интерфейс или порт GPIO должен реализовывать метод split, возвращающий структуру со всеми пинами.
Пример:
#![allow(unused)] fn main() { pub struct PA0; pub struct PA1; // ... pub struct PortA; impl PortA { pub fn split(self) -> PortAPins { PortAPins { pa0: PA0, pa1: PA1, // ... } } } pub struct PortAPins { pub pa0: PA0, pub pa1: PA1, // ... } }
Типы пинов предоставляют методы для стирания пина и порта (C-ERASED-PIN)
Пины должны предоставлять методы стирания типов, которые переводят их свойства из времени компиляции во время выполнения, обеспечивая большую гибкость в приложениях.
Пример:
#![allow(unused)] fn main() { /// Порт A, пин 0. pub struct PA0; impl PA0 { pub fn erase_pin(self) -> PA { PA { pin: 0 } } } /// Пин на порте A. pub struct PA { /// Номер пина. pin: u8, } impl PA { pub fn erase_port(self) -> Pin { Pin { port: Port::A, pin: self.pin, } } } pub struct Pin { port: Port, pin: u8, // (эти поля могут быть упакованы для уменьшения занимаемой памяти) } enum Port { A, B, C, D, } }
Состояние пина должно быть закодировано в параметрах типа (C-PIN-STATE)
Пины могут быть настроены как вход или выход с различными характеристиками в зависимости от микросхемы или семейства. Это состояние должно быть закодировано в системе типов, чтобы предотвратить использование пинов в некорректных состояниях.
Дополнительное, специфичное для микросхемы состояние (например, сила тока) также может быть закодировано таким образом с использованием дополнительных параметров типа.
Методы для изменения состояния пина должны предоставляться как into_input и into_output.
Кроме того, должны быть предоставлены методы with_input_state и with_output_state, которые временно изменяют состояние пина.
Пример:
#![allow(unused)] fn main() { use std::marker::PhantomData; mod sealed { pub trait Sealed {} } pub trait PinState: sealed::Sealed {} pub trait OutputState: sealed::Sealed {} pub trait InputState: sealed::Sealed { // ... } pub struct Output<S: OutputState> { _p: PhantomData<S>, } impl<S: OutputState> PinState for Output<S> {} impl<S: OutputState> sealed::Sealed for Output<S> {} pub struct PushPull; pub struct OpenDrain; impl OutputState for PushPull {} impl OutputState for OpenDrain {} impl sealed::Sealed for PushPull {} impl sealed::Sealed for OpenDrain {} pub struct Input<S: InputState> { _p: PhantomData<S>, } impl<S: InputState> PinState for Input<S> {} impl<S: InputState> sealed::Sealed for Input<S> {} pub struct Floating; pub struct PullUp; pub struct PullDown; impl InputState for Floating {} impl InputState for PullUp {} impl InputState for PullDown {} impl sealed::Sealed for Floating {} impl sealed::Sealed for PullUp {} impl sealed::Sealed for PullDown {} pub struct PA1<S: PinState> { _p: PhantomData<S>, } impl<S: PinState> PA1<S> { pub fn into_input<N: InputState>(self, input: N) -> PA1<Input<N>> { todo!() } pub fn into_output<N: OutputState>(self, output: N) -> PA1<Output<N>> { todo!() } pub fn with_input_state<N: InputState, R>( &mut self, input: N, f: impl FnOnce(&mut PA1<N>) -> R, ) -> R { todo!() } pub fn with_output_state<N: OutputState, R>( &mut self, output: N, f: impl FnOnce(&mut PA1<N>) -> R, ) -> R { todo!() } } // То же самое для `PA` и `Pin`, и других типов пинов. }
Советы для разработчиков на embedded C
Эта глава собирает различные советы, которые могут быть полезны опытным разработчикам на embedded C, желающим начать писать на Rust. Особое внимание будет уделено тому, как вещи, к которым вы уже привыкли в C, отличаются в Rust.
Препроцессор
В embedded C очень распространено использование препроцессора для различных целей, таких как:
- Выбор блоков кода во время компиляции с помощью
#ifdef - Размеры массивов и вычисления во время компиляции
- Макросы для упрощения общих шаблонов (чтобы избежать накладных расходов на вызов функций)
В Rust нет препроцессора, поэтому многие из этих случаев использования решаются по-другому. В остальной части этого раздела мы рассмотрим различные альтернативы использованию препроцессора.
Выбор кода во время компиляции
Наиболее близким аналогом #ifdef ... #endif в Rust являются функции Cargo. Они немного более формальны, чем препроцессор C: все возможные функции явно перечислены для каждого крейта и могут быть либо включены, либо выключены. Функции включаются при перечислении крейта как зависимости и являются аддитивными: если любой крейт в вашем дереве зависимостей включает функцию для другого крейта, эта функция будет включена для всех пользователей этого крейта.
Например, у вас может быть крейт, предоставляющий библиотеку примитивов обработки сигналов. Каждый из них может требовать дополнительного времени на компиляцию или объявлять большую таблицу констант, которую вы хотите избежать. Вы можете объявить функцию Cargo для каждого компонента в вашем Cargo.toml:
[features]
FIR = []
IIR = []
Затем в вашем коде используйте #[cfg(feature="FIR")] для управления тем, что включается.
#![allow(unused)] fn main() { /// В вашем lib.rs верхнего уровня #[cfg(feature="FIR")] pub mod fir; #[cfg(feature="IIR")] pub mod iir; }
Аналогично вы можете включать блоки кода только если функция не включена или если любая комбинация функций включена или не включена.
Кроме того, Rust предоставляет ряд автоматически устанавливаемых условий, которые вы можете использовать, таких как target_arch для выбора разного кода в зависимости от архитектуры. Для полного описания поддержки условной компиляции обратитесь к главе условная компиляция справочника Rust.
Условная компиляция применяется только к следующему утверждению или блоку. Если блок не может быть использован в текущей области видимости, то атрибут cfg нужно использовать несколько раз. Стоит отметить, что в большинстве случаев лучше просто включить весь код и позволить компилятору удалить неиспользуемый код при оптимизации: это проще для вас и ваших пользователей, и в общем случае компилятор хорошо справляется с удалением неиспользуемого кода.
Размеры и вычисления во время компиляции
Rust поддерживает const fn, функции, которые гарантированно вычисляемы во время компиляции и поэтому могут использоваться там, где требуются константы, например, в размере массивов. Это можно использовать вместе с функциями, упомянутыми выше, например:
#![allow(unused)] fn main() { const fn array_size() -> usize { #[cfg(feature="use_more_ram")] { 1024 } #[cfg(not(feature="use_more_ram"))] { 128 } } static BUF: [u32; array_size()] = [0u32; array_size()]; }
Это новинка в стабильном Rust с версии 1.31, поэтому документация все еще скудна. Функциональность, доступная для const fn, также очень ограничена на момент написания; в будущих релизах Rust ожидается расширение того, что разрешено в const fn.
Макросы
Rust предоставляет чрезвычайно мощную систему макросов. В то время как препроцессор C работает почти напрямую с текстом вашего исходного кода, система макросов Rust работает на более высоком уровне. Существуют два вида макросов Rust: макросы по примеру и процедурные макросы. Первые проще и наиболее распространены; они выглядят как вызовы функций и могут расширяться в полное выражение, утверждение, элемент или шаблон. Процедурные макросы более сложны, но позволяют чрезвычайно мощные дополнения к языку Rust: они могут преобразовывать произвольный синтаксис Rust в новый синтаксис Rust.
В общем, там, где вы могли бы использовать макрос препроцессора C, вы, вероятно, хотите посмотреть, может ли макрос по примеру справиться с задачей. Они могут быть определены в вашем крейте и легко использоваться вашим крейтом или экспортироваться для других пользователей. Имейте в виду, что поскольку они должны расширяться в полные выражения, утверждения, элементы или шаблоны, некоторые случаи использования макросов препроцессора C не будут работать, например, макрос, который расширяется в часть имени переменной или неполный набор элементов в списке.
Как и с функциями Cargo, стоит подумать, нужен ли вам макрос вообще. Во многих случаях обычная функция проще для понимания и будет встроена в тот же код, что и макрос. Атрибуты #[inline] и #[inline(always)] attributes дают вам дополнительный контроль над этим процессом, хотя здесь тоже следует проявлять осторожность — компилятор автоматически встраивает функции из того же крейта, где это уместно, так что принуждение к этому неуместно может привести к снижению производительности.
Объяснение всей системы макросов Rust выходит за рамки этой страницы советов, поэтому рекомендуется обратиться к документации Rust за полными деталями.
Система сборки
Большинство крейтов Rust собираются с использованием Cargo (хотя это не обязательно). Это решает многие сложные проблемы традиционных систем сборки. Однако вы можете захотеть настроить процесс сборки. Cargo предоставляет скрипты build.rs для этой цели. Это скрипты на Rust, которые могут взаимодействовать с системой сборки Cargo по мере необходимости.
Общие случаи использования скриптов сборки включают:
- предоставление информации во время сборки, например, статическое встраивание даты сборки или хэша коммита Git в исполняемый файл
- генерация скриптов линковки во время сборки в зависимости от выбранных функций или другой логики
- изменение конфигурации сборки Cargo
- добавление дополнительных статических библиотек для линковки
На данный момент нет поддержки скриптов после сборки, которые вы могли бы традиционно использовать для задач, таких как автоматическая генерация бинарных файлов из объектов сборки или печать информации о сборке.
Кросс-компиляция
Использование Cargo для системы сборки также упрощает кросс-компиляцию. В большинстве случаев достаточно указать Cargo --target thumbv6m-none-eabi и найти подходящий исполняемый файл в target/thumbv6m-none-eabi/debug/myapp.
Для платформ, не поддерживаемых Rust нативно, вам нужно будет собрать libcore для этой цели самостоятельно. На таких платформах можно использовать Xargo как замену Cargo, который автоматически собирает libcore для вас.
Итераторы против доступа к массиву
В C вы, вероятно, привыкли обращаться к массивам напрямую по индексу:
int16_t arr[16];
int i;
for(i = 0; i < sizeof(arr)/sizeof(arr[0]); i++) {
arr[i] = i;
}
В Rust предпочтительным подходом является использование итераторов, которые часто более безопасны и выразительны. Например:
#![allow(unused)] fn main() { let mut arr = [0i16; 16]; for (i, v) in arr.iter_mut().enumerate() { *v = i as i16; } }
Итераторы в Rust позволяют избежать ошибок, связанных с выходом за границы массива, и предоставляют мощные методы для обработки данных. Однако в контексте embedded, где производительность критична, иногда может потребоваться прямой доступ к массиву, как в C. В таких случаях вы можете использовать индексацию, но будьте осторожны с проверкой границ:
#![allow(unused)] fn main() { let mut arr = [0i16; 16]; for i in 0..arr.len() { arr[i] = i as i16; } }
Указатели
В C указатели — это фундаментальная часть языка, используемая для прямого доступа к памяти, особенно в embedded-разработке. В Rust указатели существуют, но их использование ограничено из-за системы владения и заимствования. В Rust есть два типа сырых указателей: *const T и *mut T. Они похожи на указатели в C в том смысле, что их можно разыменовать для доступа к базовым значениям, но они являются ключевой частью системы владения Rust: Rust строго обеспечивает, что у вас может быть только одна изменяемая ссылка или несколько неизменяемых ссылок на одно и то же значение в любой момент времени.
На практике это означает, что вы должны быть более осторожны с тем, нужен ли вам изменяемый доступ к данным: если в C по умолчанию все изменяемо и вы должны явно указывать const, в Rust наоборот.
Одна ситуация, когда вы все еще можете использовать сырые указатели, — это прямое взаимодействие с аппаратным обеспечением (например, запись указателя на буфер в регистр DMA), и они также используются под капотом во всех крейтах доступа к периферийным устройствам, чтобы позволить вам читать и записывать регистры с отображением в память.
Волатильный доступ
В C отдельные переменные могут быть помечены как volatile, что указывает компилятору, что значение переменной может измениться между обращениями. Волатильные переменные обычно используются в контексте embedded для регистров с отображением в память.
В Rust вместо пометки переменной как volatile мы используем специальные методы для выполнения волатильного доступа: core::ptr::read_volatile и core::ptr::write_volatile. Эти методы принимают *const T или *mut T (сырые указатели, как обсуждалось выше) и выполняют волатильное чтение или запись.
Например, в C вы могли бы написать:
volatile bool signalled = false;
void ISR() {
// Сигнализируем, что прерывание произошло
signalled = true;
}
void driver() {
while(true) {
// Спим до сигнала
while(!signalled) { WFI(); }
// Сбрасываем индикатор сигнала
signalled = false;
// Выполняем задачу, ожидающую прерывания
run_task();
}
}
Эквивалент в Rust использовал бы волатильные методы для каждого доступа:
static mut SIGNALLED: bool = false;
#[interrupt]
fn ISR() {
// Сигнализируем, что прерывание произошло
// (В реальном коде следует рассмотреть примитив более высокого уровня,
// например, атомарный тип).
unsafe { core::ptr::write_volatile(&mut SIGNALLED, true) };
}
fn driver() {
loop {
// Спим до сигнала
while unsafe { !core::ptr::read_volatile(&SIGNALLED) } {}
// Сбрасываем индикатор сигнала
unsafe { core::ptr::write_volatile(&mut SIGNALLED, false) };
// Выполняем задачу, ожидающую прерывания
run_task();
}
}Несколько моментов, которые стоит отметить в примере кода:
- Мы можем передать
&mut SIGNALLEDв функцию, требующую*mut T, поскольку&mut Tавтоматически преобразуется в*mut T(и то же самое для*const T) - Нам нужны блоки
unsafeдля методовread_volatile/write_volatile, поскольку это небезопасные функции. Ответственность за обеспечение безопасного использования лежит на программисте: подробности см. в документации методов.
Прямое использование этих функций в вашем коде редко требуется, так как они обычно обрабатываются библиотеками более высокого уровня. Для регистров с отображением в память крейты доступа к периферийным устройствам автоматически реализуют волатильный доступ, в то время как для примитивов параллелизма доступны лучшие абстракции (см. главу Параллелизм).
Упакованные и выровненные типы
В embedded C часто указывают компилятору, что переменная должна иметь определенное выравнивание или структура должна быть упакована, а не выровнена, обычно для соответствия требованиям аппаратного обеспечения или протокола.
В Rust это контролируется атрибутом repr для структуры или объединения. Представление по умолчанию не предоставляет гарантий компоновки, поэтому его не следует использовать для кода, взаимодействующего с аппаратным обеспечением или C. Компилятор может переупорядочить члены структуры или вставить заполнение, и поведение может измениться в будущих версиях Rust.
struct Foo { x: u16, y: u8, z: u16, } fn main() { let v = Foo { x: 0, y: 0, z: 0 }; println!("{:p} {:p} {:p}", &v.x, &v.y, &v.z); } // 0x7ffecb3511d0 0x7ffecb3511d4 0x7ffecb3511d2 // Обратите внимание, что порядок изменен на x, z, y для улучшения упаковки.
Чтобы обеспечить компоновку, совместимую с C, используйте repr(C):
#[repr(C)] struct Foo { x: u16, y: u8, z: u16, } fn main() { let v = Foo { x: 0, y: 0, z: 0 }; println!("{:p} {:p} {:p}", &v.x, &v.y, &v.z); } // 0x7fffd0d84c60 0x7fffd0d84c62 0x7fffd0d84c64 // Порядок сохранен, и компоновка не изменится со временем. // `z` выровнен по двум байтам, поэтому между `y` и `z` существует байт заполнения.
Для обеспечения упакованного представления используйте repr(packed):
#[repr(packed)] struct Foo { x: u16, y: u8, z: u16, } fn main() { let v = Foo { x: 0, y: 0, z: 0 }; // Ссылки всегда должны быть выровнены, поэтому для проверки адресов полей структуры // мы используем `std::ptr::addr_of!()` для получения сырого указателя // вместо простого вывода `&v.x`. let px = std::ptr::addr_of!(v.x); let py = std::ptr::addr_of!(v.y); let pz = std::ptr::addr_of!(v.z); println!("{:p} {:p} {:p}", px, py, pz); } // 0x7ffd33598490 0x7ffd33598492 0x7ffd33598493 // Между `y` и `z` не вставлено заполнение, поэтому теперь `z` не выровнен.
Обратите внимание, что использование repr(packed) также устанавливает выравнивание типа в 1.
Наконец, чтобы указать конкретное выравнивание, используйте repr(align(n)), где n — это количество байтов для выравнивания (и должно быть степенью двойки):
#[repr(C)] #[repr(align(4096))] struct Foo { x: u16, y: u8, z: u16, } fn main() { let v = Foo { x: 0, y: 0, z: 0 }; let u = Foo { x: 0, y: 0, z: 0 }; println!("{:p} {:p} {:p}", &v.x, &v.y, &v.z); println!("{:p} {:p} {:p}", &u.x, &u.y, &u.z); } // 0x7ffec909a000 0x7ffec909a002 0x7ffec909a004 // 0x7ffec909b000 0x7ffec909b002 0x7ffec909b004 // Два экземпляра `u` и `v` размещены с выравниванием по 4096 байтам, // о чем свидетельствует `000` в конце их адресов.
Обратите внимание, что мы можем комбинировать repr(C) с repr(align(n)) для получения выровненной и совместимой с C компоновки. Нельзя комбинировать repr(align(n)) с repr(packed), поскольку repr(packed) устанавливает выравнивание в 1. Также недопустимо, чтобы тип repr(packed) содержал тип repr(align(n)).
Для дополнительной информации о компоновке типов обратитесь к главе компоновка типов справочника Rust.
Другие ресурсы
- В этой книге:
- Часто задаваемые вопросы по Rust Embedded
- Указатели Rust для программистов на C
- Я использовал указатели — что теперь?
Интероперабельность
Интероперабельность между кодом на Rust и C всегда зависит от преобразования данных между двумя языками. Для этой цели в stdlib есть специальный модуль, называемый std::ffi.
std::ffi предоставляет определения типов для примитивов C, таких как char, int и long. Также он предоставляет утилиты для преобразования более сложных типов, таких как строки, отображая как &str, так и String на типы C, которые легче и безопаснее обрабатывать.
Начиная с Rust 1.30, функциональность std::ffi доступна либо в core::ffi, либо в alloc::ffi, в зависимости от того, связано ли это с выделением памяти. Крейты cty и cstr_core также предлагают аналогичные функциональности.
| Тип Rust | Промежуточный | Тип C |
|---|---|---|
String | CString | char * |
&str | CStr | const char * |
() | c_void | void |
u32 или u64 | c_uint | unsigned int |
| и т.д. | ... | ... |
Значение типа-примитива C можно использовать как соответствующий тип Rust и наоборот, поскольку первый является просто псевдонимом второго. Например, следующий код компилируется на платформах, где unsigned int имеет длину 32 бита:
fn foo(num: u32) {
let c_num: c_uint = num;
let r_num: u32 = c_num;
}Интероперабельность с другими системами сборки
Общим требованием для включения Rust в ваш проект для встраиваемых систем является объединение Cargo с вашей существующей системой сборки, такой как make или cmake.
Мы собираем примеры и случаи использования для этого в нашем трекере задач в issue #61.
Интероперабельность с RTOS
Интеграция Rust с RTOS, такими как FreeRTOS или ChibiOS, все еще находится в стадии разработки; особенно вызов функций RTOS из Rust может быть сложным.
Мы собираем примеры и случаи использования для этого в нашем трекере задач в issue #62.
Немного C в вашем Rust
Использование кода на C или C++ внутри проекта на Rust состоит из двух основных частей:
- Обертывание открытого API на C для использования в Rust
- Сборка кода на C или C++ для интеграции с кодом на Rust
Поскольку C++ не имеет стабильного ABI для компилятора Rust, рекомендуется использовать ABI C при комбинировании Rust с C или C++.
Определение интерфейса
Перед использованием кода на C или C++ из Rust необходимо определить (на Rust) типы данных и сигнатуры функций, существующие в связанном коде. В C или C++ вы бы подключили заголовочный файл (.h или .hpp), который определяет эти данные. В Rust необходимо либо вручную перевести эти определения в Rust, либо использовать инструмент для их автоматической генерации.
Сначала мы рассмотрим ручной перевод этих определений из C/C++ в Rust.
Обертывание функций и типов данных C
Обычно библиотеки, написанные на C или C++, предоставляют заголовочный файл, определяющий все типы и функции, используемые в публичных интерфейсах. Пример такого файла может выглядеть следующим образом:
/* File: cool.h */
typedef struct CoolStruct {
int x;
int y;
} CoolStruct;
void cool_function(int i, char c, CoolStruct* cs);
При переводе в Rust этот интерфейс будет выглядеть так:
/* File: cool_bindings.rs */
#[repr(C)]
pub struct CoolStruct {
pub x: cty::c_int,
pub y: cty::c_int,
}
extern "C" {
pub fn cool_function(
i: cty::c_int,
c: cty::c_char,
cs: *mut CoolStruct
);
}Разберем это определение по частям, чтобы объяснить каждый компонент.
#[repr(C)]
pub struct CoolStruct { ... }По умолчанию Rust не гарантирует порядок, выравнивание или размер данных, включенных в struct. Чтобы обеспечить совместимость с кодом на C, мы используем атрибут #[repr(C)], который указывает компилятору Rust всегда использовать те же правила, что и C, для организации данных внутри структуры.
pub x: cty::c_int,
pub y: cty::c_int,Из-за гибкости определения int или char в C или C++ рекомендуется использовать типы из модуля cty, такие как c_int и c_char, чтобы обеспечить совместимость с платформой.
extern "C" {
pub fn cool_function(
i: cty::c_int,
c: cty::c_char,
cs: *mut CoolStruct
);
}Блок extern "C" сообщает компилятору Rust, что указанные функции используют ABI C, обеспечивая их совместимость с функциями, определенными в коде на C. Указатель *mut CoolStruct соответствует указателю CoolStruct* в C, позволяя передавать изменяемые структуры между языками.
Автоматизация с помощью bindgen
Ручной перевод заголовочных файлов может быть трудоемким и подверженным ошибкам, особенно для больших библиотек. Инструмент bindgen автоматизирует этот процесс, генерируя определения Rust из заголовочных файлов C или C++.
Чтобы использовать bindgen, добавьте его в зависимости вашего проекта в Cargo.toml:
[build-dependencies]
bindgen = "0.59"
Затем создайте скрипт build.rs для генерации привязок:
use bindgen;
fn main() {
println!("cargo:rerun-if-changed=wrapper.h");
bindgen::Builder::default()
.header("wrapper.h")
.generate()
.expect("Unable to generate bindings")
.write_to_file("src/bindings.rs")
.expect("Couldn't write bindings!");
}Файл wrapper.h должен включать заголовочные файлы C, которые вы хотите преобразовать:
/* wrapper.h */
#include "cool.h"
Запуск cargo build сгенерирует файл src/bindings.rs, содержащий определения Rust для всех типов и функций из cool.h. Используйте их в вашем коде на Rust:
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));Сборка кода на C/C++
После определения интерфейса необходимо скомпилировать код на C или C++ и связать его с вашим проектом на Rust. Это обычно делается с помощью скрипта build.rs.
Скрипты сборки
Скрипт build.rs — это файл, написанный на синтаксисе Rust, который выполняется на вашей машине компиляции ПОСЛЕ сборки зависимостей вашего проекта, но ДО сборки самого проекта.
Полное описание можно найти здесь. Скрипты build.rs полезны для генерации кода (например, через [bindgen]), вызова внешних систем сборки, таких как Make, или прямой компиляции C/C++ с использованием крейта cc.
Вызов внешних систем сборки
Для проектов с сложными внешними проектами или системами сборки проще всего использовать std::process::Command для вызова других систем сборки, переходя по относительным путям, вызывая фиксированную команду (например, make library) и затем копируя полученную статическую библиотеку в нужное место в директории сборки target.
Хотя ваш крейт может быть нацелен на платформу no_std, ваш build.rs выполняется только на машинах, компилирующих ваш крейт. Это означает, что вы можете использовать любые крейты Rust, которые работают на вашем хосте компиляции.
Сборка кода на C/C++ с помощью крейта cc
Для проектов с ограниченными зависимостями или сложностью, или для проектов, где трудно модифицировать систему сборки для создания статической библиотеки (вместо финального бинарного файла или исполняемого файла), проще использовать крейт [cc], который предоставляет идиоматичный интерфейс Rust к компилятору, предоставляемому хостом.
В простейшем случае компиляции одного файла C в качестве зависимости для статической библиотеки пример скрипта build.rs, использующего крейт [cc], будет выглядеть так:
fn main() {
cc::Build::new()
.file("src/foo.c")
.compile("foo");
}Файл build.rs размещается в корне пакета. Затем cargo build скомпилирует и выполнит его перед сборкой пакета. Генерируется статический архив с именем libfoo.a, который помещается в директорию target.
Немного Rust в вашем C
Использование кода на Rust внутри проекта на C или C++ в основном состоит из двух частей:
- Создание API, совместимого с C, на Rust
- Встраивание вашего проекта на Rust во внешнюю систему сборки
Помимо cargo и meson, большинство систем сборки не имеют встроенной поддержки Rust. Поэтому, скорее всего, лучше всего использовать cargo для компиляции вашего крейта и любых его зависимостей.
Настройка проекта
Создайте новый проект cargo как обычно.
Есть флаги, чтобы указать cargo генерировать системную библиотеку вместо обычной цели Rust. Это также позволяет задать другое имя выходной библиотеки, если вы хотите, чтобы оно отличалось от остальной части вашего крейта.
[lib]
name = "your_crate"
crate-type = ["cdylib"] # Создает динамическую библиотеку
# crate-type = ["staticlib"] # Создает статическую библиотеку
Создание API для C
Поскольку C++ не имеет стабильного ABI для компилятора Rust, мы используем C для любой интероперабельности между разными языками. Это не исключение при использовании Rust внутри кода на C и C++.
#[no_mangle]
Компилятор Rust искажает имена символов иначе, чем ожидают компоновщики нативного кода. Поэтому любая функция, которую Rust экспортирует для использования вне Rust, должна быть помечена так, чтобы компилятор не искажал ее имя.
extern "C"
По умолчанию любая функция, написанная на Rust, использует ABI Rust (который также не стабилизирован). Вместо этого, при создании внешних API FFI, нам нужно указать компилятору использовать системный ABI.
В зависимости от вашей платформы, вы можете захотеть нацелиться на конкретную версию ABI, которые задокументированы здесь.
Собирая эти части вместе, вы получаете функцию, которая выглядит примерно так:
#[no_mangle]
pub extern "C" fn rust_function() {
}Как и при использовании кода на C в вашем проекте на Rust, вам теперь нужно преобразовывать данные в форму, понятную остальной части приложения.
Компоновка и общий контекст проекта
Итак, одна половина проблемы решена. Как теперь это использовать?
Это очень сильно зависит от вашего проекта и/или системы сборки
cargo создаст файл my_lib.so/my_lib.dll или my_lib.a в зависимости от вашей платформы и настроек. Эту библиотеку можно просто слинковать вашей системой сборки.
Однако вызов функции Rust из C требует заголовочного файла для объявления сигнатур функций.
Каждая функция в вашем Rust-FFI API должна иметь соответствующую функцию в заголовочном файле.
#[no_mangle]
pub extern "C" fn rust_function() {}будет преобразована в
void rust_function();
и т.д.
Существует инструмент для автоматизации этого процесса, называемый cbindgen, который анализирует ваш код на Rust и генерирует заголовочные файлы для ваших проектов на C и C++.
На этом этапе использование функций Rust из C так же просто, как включение заголовочного файла и их вызов!
#include "my-rust-project.h"
rust_function();
Несортированные темы
Оптимизации: компромисс между скоростью и размером
Каждый хочет, чтобы его программа была очень быстрой и очень компактной, но обычно невозможно достичь обеих характеристик одновременно. В этом разделе обсуждаются различные уровни оптимизации, предоставляемые компилятором rustc, и их влияние на время выполнения и размер бинарного файла программы.
Без оптимизаций
Это настройка по умолчанию. Когда вы вызываете cargo build, используется профиль разработки (также известный как dev). Этот профиль оптимизирован для отладки, поэтому он включает отладочную информацию и не включает никаких оптимизаций, т.е. используется -C opt-level = 0.
По крайней мере, для разработки без операционной системы отладочная информация не занимает места во флэш-памяти / ПЗУ, поэтому мы рекомендуем включать отладочную информацию в профиле выпуска — по умолчанию она отключена. Это позволит использовать точки останова при отладке сборок выпуска.
[profile.release]
# символы полезны, и они не увеличивают размер во флэш-памяти
debug = true
Отсутствие оптимизаций отлично подходит для отладки, поскольку пошаговое выполнение кода ощущается как выполнение программы оператор за оператором, плюс вы можете выводить значения локальных переменных и аргументов функций в GDB. При оптимизированном коде попытка вывести переменные приводит к сообщению $0 = <value optimized out>.
Самый большой недостаток профиля dev заключается в том, что получаемый бинарный файл будет огромным и медленным. Размер обычно представляет большую проблему, поскольку неоптимизированные бинарные файлы могут занимать десятки килобайт флэш-памяти, которой может не быть на вашем целевом устройстве — в результате неоптимизированный бинарный файл просто не помещается в ваше устройство!
Можно ли получить меньшие бинарные файлы, удобные для отладки? Да, есть один прием.
Оптимизация зависимостей
Есть функция Cargo под названием profile-overrides, которая позволяет переопределять уровень оптимизации для зависимостей. Вы можете использовать эту функцию, чтобы оптимизировать все зависимости для размера, сохраняя верхний крейт неоптимизированным и удобным для отладки.
Учтите, что обобщенный код может быть проблематичным при использовании различных уровней оптимизации, поэтому вам может потребоваться экспериментировать с настройками.
Оптимизация для скорости
Если вы хотите, чтобы ваши бинарные файлы выпуска были оптимизированы для скорости, измените настройку profile.release.opt-level в Cargo.toml, как показано ниже:
[profile.release]
opt-level = 3
или
[profile.release]
opt-level = 2
Эти два уровня оптимизации (opt-level = 2 и 3) значительно увеличивают производительность, но также могут увеличивать размер бинарного файла. Если вы не можете позволить себе увеличение размера, вам следует оптимизировать программу для размера.
Оптимизация для размера
По состоянию на 18.09.2018 rustc поддерживает два уровня оптимизации для размера: opt-level = "s" и "z". Эти названия унаследованы от clang / LLVM и не слишком описательны, но "z" подразумевает, что он производит бинарные файлы меньшего размера, чем "s".
Если вы хотите, чтобы ваши бинарные файлы выпуска были оптимизированы для размера, измените настройку profile.release.opt-level в Cargo.toml, как показано ниже:
[profile.release]
# или "z"
opt-level = "s"
Эти два уровня оптимизации значительно снижают порог встраивания LLVM, метрику, используемую для принятия решения о встраивании функции. Одним из принципов Rust являются абстракции с нулевой стоимостью; эти абстракции часто используют множество новых типов и небольших функций для сохранения инвариантов (например, функции, которые заимствуют внутреннее значение, такие как deref, as_ref), поэтому низкий порог встраивания может привести к тому, что LLVM упустит возможности оптимизации (например, устранение мертвых ветвей, встраивание вызовов замыканий).
При оптимизации для размера вы можете попробовать увеличить порог встраивания, чтобы проверить, влияет ли это на размер бинарного файла. Рекомендуемый способ изменения порога встраивания — добавить флаг -C inline-threshold к другим флагам rustflags в .cargo/config.toml:
# .cargo/config.toml
# предполагается, что используется шаблон cortex-m-quickstart
[target.'cfg(all(target_arch = "arm", target_os = "none"))']
rustflags = [
# ..
"-C", "inline-threshold=123", # +
]
Какое значение использовать? По состоянию на версию 1.29.0 следующие пороги встраивания используются для разных уровней оптимизации:
opt-level = 3использует 275opt-level = 2использует 225opt-level = "s"использует 75opt-level = "z"использует 25
При оптимизации для размера стоит попробовать значения 225 и 275.
Выполнение математических операций с #[no_std]
Если вы хотите выполнять математические операции, такие как вычисление квадратного корня или экспоненты числа, и у вас доступна полная стандартная библиотека, ваш код может выглядеть следующим образом:
//! Некоторые математические функции с доступной стандартной библиотекой
fn main() {
let float: f32 = 4.82832;
let floored_float = float.floor();
let sqrt_of_four = floored_float.sqrt();
let sinus_of_four = floored_float.sin();
let exponential_of_four = floored_float.exp();
println!("Округлено вниз тестовое число {} до {}", float, floored_float);
println!("Квадратный корень из {} равен {}", floored_float, sqrt_of_four);
println!("Синус числа четыре равен {}", sinus_of_four);
println!(
"Экспонента числа четыре с основанием e равна {}",
exponential_of_four
)
}
Без поддержки стандартной библиотеки эти функции недоступны. Вместо этого можно использовать внешний крейт, например libm. Пример кода в этом случае будет выглядеть так:
#![no_main]
#![no_std]
use panic_halt as _;
use cortex_m_rt::entry;
use cortex_m_semihosting::{debug, hprintln};
use libm::{exp, floorf, sin, sqrtf};
#[entry]
fn main() -> ! {
let float = 4.82832;
let floored_float = floorf(float);
let sqrt_of_four = sqrtf(floored_float);
let sinus_of_four = sin(floored_float.into());
let exponential_of_four = exp(floored_float.into());
hprintln!("Округлено вниз тестовое число {} до {}", float, floored_float).unwrap();
hprintln!("Квадратный корень из {} равен {}", floored_float, sqrt_of_four).unwrap();
hprintln!("Синус числа четыре равен {}", sinus_of_four).unwrap();
hprintln!(
"Экспонента числа четыре с основанием e равна {}",
exponential_of_four
)
.unwrap();
// Выход из QEMU
// ПРИМЕЧАНИЕ: не запускайте это на оборудовании; это может повредить состояние OpenOCD
// debug::exit(debug::EXIT_SUCCESS);
loop {}
}
Если вам нужно выполнять более сложные операции, такие как обработка сигналов DSP или продвинутая линейная алгебра на вашем микроконтроллере, следующие крейты могут быть полезны:
Приложение A: Глоссарий
Экосистема встраиваемых систем полна различных протоколов, аппаратных компонентов и специфичных для производителей терминов и аббревиатур. Этот глоссарий стремится перечислить их с указателями для лучшего понимания.
BSP
Крейт поддержки платы (Board Support Crate) предоставляет высокоуровневый интерфейс, настроенный для конкретной платы. Обычно он зависит от крейта HAL. Более подробное описание можно найти на странице о регистрах с отображением в память или для более общего обзора смотрите это видео.
FPU
Блок операций с плавающей запятой (Floating-point Unit). "Математический процессор", выполняющий операции только с числами с плавающей запятой.
HAL
Крейт уровня абстракции аппаратного обеспечения (Hardware Abstraction Layer) предоставляет удобный для разработчика интерфейс к функциям и периферийным устройствам микроконтроллера. Обычно он реализуется поверх крейта Peripheral Access Crate (PAC).
Также он может реализовывать трейты из крейта embedded-hal.
Более подробное описание можно найти на странице о регистрах с отображением в память
или для более общего обзора смотрите это видео.
I2C
Иногда обозначается как I²C или Inter-IC. Это протокол, предназначенный для коммуникации между аппаратными компонентами внутри одной интегральной схемы. Подробности смотрите здесь.
PAC
Крейт доступа к периферийным устройствам (Peripheral Access Crate) предоставляет доступ к периферийным устройствам микроконтроллера. Это один из низкоуровневых крейтов, который обычно генерируется непосредственно из предоставленного SVD, часто с использованием svd2rust. Крейт уровня абстракции аппаратного обеспечения обычно зависит от этого крейта. Более подробное описание можно найти на странице о регистрах с отображением в память или для более общего обзора смотрите это видео.
SPI
Интерфейс периферийных устройств (Serial Peripheral Interface). Подробности смотрите здесь.
SVD
Описание системного вида (System View Description) — это формат XML-файла, используемый для описания представления микроконтроллера с точки зрения программиста. Подробности можно прочитать на сайте документации ARM CMSIS.
UART
Универсальный асинхронный приёмопередатчик (Universal Asynchronous Receiver-Transmitter). Подробности смотрите здесь.
USART
Универсальный синхронный и асинхронный приёмопередатчик (Universal Synchronous and Asynchronous Receiver-Transmitter). Подробности смотрите здесь.